
Cómo calcular resúmenes por grupo rápidamente
¿Sabes cómo calcular resúmenes estadísticos rápidos sin necesidad de utilizar bucles o crear funciones propias? o ¿cómo hacer para que estos resúmenes se calculen en cada grupo de datos por separado?En R tenemos varias funciones que nos permiten repetir una misma tarea sobre unos objetos sin la necesidad de tener que escribir un bucle ni crear una función.
En una única línea de código y de manera más eficiente!
Por ejemplo, podemos pedirle a R que calcule la media de todas las columnas de nuestra base de datos en una única línea de comando.
Hoy veremos la familia de funciones «apply», la función «by», «aggregate», «ddlyr» y «summaryBy».
¿Cómo trabajan estas funciones?
Pues, cada una se aplica para objetos distintos (vectores, data frames, matrices, listas, etc.) y nos dan un resultado en un formato distinto.
(Casi) todo en R es un objeto, pero… ¡existen distintos tipos de objetos!
ÚLTIMAS PLAZAS EN MASTERS
Máster Data Science
CONVOCATORIA ABIERTA I Logra la máxima precisión y rigor en tus proyectos de Ciencia de Datos.
Ver convocatorias 2022MAster en MAchine learning
CONVOCATORIA ABIERTA | Automatiza procesos y crea tus propios algoritmos de Machine Learning.
Ver convocatorias 2022Tipos de objetos:
- vectores (un conjunto de elementos del mismo tipo) o factores (si está formado por categorías -categórico-). Por ejemplo, x={hombre, mujer}
- conjuntos de vectores en 2D llamados matrices o data frames (si la matriz tiene datos de distinto tipo -numéricos y categóricos-), Por ejemplo, una matriz donde en las filas tenemos la respuesta de cada sujeto y en las columnas las preguntas que se le hicieron.
- conjuntos de vectores en más de 2D llamados arrays. Si en el ejemplo anterior tenemos una matriz de datos para cada comunidad autónoma, entonces podemos construir un array.
- o listas (lista de varios tipos de elementos). Si además de las matrices de datos agregamos «metadata», es decir, información como la fecha de la toma de la muestra, etc.
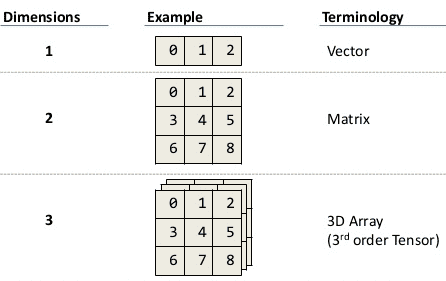
Entonces, según qué tipo de objeto de entrada (argumento) y salida vayamos a utilizar, podemos elegir entre distintas funciones para realizar nuestros resúmenes estadísticos.
En la siguiente tabla puedes ver un resumen de las principales funciones, luego veremos su aplicación en R.
¿Qué función elegir para resumir nuestros datos?
FAMILIA «APPLY»
La familia de funciones «apply» se diferencian según el tipo de datos de entrada y el resultado de su aplicación del siguiente modo:
Veamos algunos ejemplos con los datos «iris»:
> str(iris) 'data.frame': 150 obs. of 5 variables: $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ... $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ... $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ... $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ... $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 …
APPLY
- «apply» se utiliza cuando queremos aplicar una función a las filas o columnas de una matriz o data frame(o dimensión de un array); generalmente no funciona para data frames a no ser que se transforme a matriz previamente.
> apply(iris[,-5],2,mean) Sepal.Length Sepal.Width Petal.Length Petal.Width 5.843333 3.057333 3.758000 1.199333 > apply(iris[,-5], 2, fivenum) Sepal.Length Sepal.Width Petal.Length Petal.Width [1,] 4.3 2.0 1.00 0.1 [2,] 5.1 2.8 1.60 0.3 [3,] 5.8 3.0 4.35 1.3 [4,] 6.4 3.3 5.10 1.8 [5,] 7.9 4.4 6.90 2.5
SAPPLY
- «sapply» se utiliza cuando queremos aplicar una función a cada elemento de una lista o data frame y obtener un vector, matriz o una lista simplificado como resultado.
> sapply(iris[,-5], mean) Sepal.Length Sepal.Width Petal.Length Petal.Width 5.843333 3.057333 3.758000 1.199333 > sapply(iris[,-5], fivenum) Sepal.Length Sepal.Width Petal.Length Petal.Width [1,] 4.3 2.0 1.00 0.1 [2,] 5.1 2.8 1.60 0.3 [3,] 5.8 3.0 4.35 1.3 [4,] 6.4 3.3 5.10 1.8 [5,] 7.9 4.4 6.90 2.5
LAPPLY
- «lapply» se utiliza cuando queremos aplicar una función a cada elemento de una lista y obtener otra lista como resultado.
> lapply(iris[,-5],mean) $Sepal.Length [1] 5.843333 $Sepal.Width [1] 3.057333 $Petal.Length [1] 3.758 $Petal.Width [1] 1.199333 > lapply(iris[,-5], fivenum) $Sepal.Length [1] 4.3 5.1 5.8 6.4 7.9 $Sepal.Width [1] 2.0 2.8 3.0 3.3 4.4 $Petal.Length [1] 1.00 1.60 4.35 5.10 6.90 $Petal.Width [1] 0.1 0.3 1.3 1.8 2.5
TAPPLY
- «tapply» se utiliza cuando queremos aplicar una función a subconjuntos de un vector (estos subconjuntos se definen con un vector o factor) y obtener un vector como resultado.
> tapply(iris$Petal.Length, iris$Species, mean) setosa versicolor virginica 1.462 4.260 5.552
OTRAS
- «vapply» es similares a las dos anteriores pero podemos decirle a R qué tipo de objeto queremos como resultado.
> vapply(iris[,-5], fivenum, c(Min.=0, "1st Qu."=0, Median=0, "3rd Qu."=0, Max.=0)) Sepal.Length Sepal.Width Petal.Length Petal.Width Min. 4.3 2.0 1.00 0.1 1st Qu. 5.1 2.8 1.60 0.3 Median 5.8 3.0 4.35 1.3 3rd Qu. 6.4 3.3 5.10 1.8 Max. 7.9 4.4 6.90 2.5
- «mapply» se utiliza cuando queremos aplicar una función a varios tipos de estructuras (e.g. vectores, listas), a sus primeros elementos, luego a los segundos, etc. y obtener como resultado un vector o array.
- «rapply» se utiliza cuando queremos aplicar una función a cada elemento de un objeto con estructura de lista anidada (una lista dentro de una lista), de manera recursiva.
Las funciones «by» y «aggregate».
Ambas son similares a «tapply» pero con algunas pequeñas diferencias, veámoslas!
BY
La diferencia entre «by» y «tapply» es:
1) la clase de resultado, porque «by» devuelve una lista.
2) algunas peculiaridades respecto al tamaño de los objetos.
> tapply(iris$Sepal.Width , iris$Species , mean ) setosa versicolor virginica 3.428 2.770 2.974 > > by(iris$Sepal.Width , iris$Species , mean ) iris$Species: setosa [1] 3.428 ------------------------------------------------------- iris$Species: versicolor [1] 2.77 ------------------------------------------------------- iris$Species: virginica [1] 2.974
3) La función «by» funciona también cuando el tamaño de los 2 primeros argumentos son distintos, cuestión no resuelta por tapply.
tapply(iris, iris$Species, summary ) Error in tapply(iris, iris$Species, summary): arguments must have same length
AGGREGATE
La función «aggregate» también se comporta de manera similar a «tapply» aunque:
1) El segundo argumento de «aggregate» debe ser una lista, mientras que para «tapply» puede ser una lista o no.
2) y el resultado es de clase distinta, para «aggregate» el resultado es un «data frame» mientras que para tapply es un «array»:
> tapply(iris$Sepal.Length , iris$Species , mean) setosa versicolor virginica 5.006 5.936 6.588 > aggregate(iris$Sepal.Length , list(iris$Species), mean) Group.1 x 1 setosa 5.006 2 versicolor 5.936 3 virginica 6.588
3) La función «aggregate» también tiene la ventaja de la opción «subset» que permite seleccionar un subconjunto de datos.
4) La función «aggregate» es más sencilla de utilizar porque permite el formato de fórmula:
> aggregate(Sepal.Length ~ Species, data = iris, mean) Species Sepal.Length 1 setosa 5.006 2 versicolor 5.936 3 virginica 6.588
DOS FUNCIONES AÚN MÁS SENCILLAS
Además de aggregate, by y tapply, podemos utilizar 2 funciones más rápidas para realizar cálculos por grupos incluso utilizando fórmulas!
Estas funciones se encuentran en paquetes extra de R (no en los que vienen instalados por defecto, como ocurre en las funicones anteriores) son:
- ddplyr (del paquete plyr) y
- summaryBy (del paquete doBy).
DDPLYR
La función «ddply» del paquete «plyr» permite aplicar una función a un data frame para cada subconjunto de datos que le indiquemos y combinar los resultados en otro data frame (además sirve para dividir un conjunto de datos)
> library(plyr)
> ddply(iris, "Species", colwise(mean))
Species Sepal.Length Sepal.Width Petal.Length Petal.Width
1 setosa 5.006 3.428 1.462 0.246
2 versicolor 5.936 2.770 4.260 1.326
3 virginica 6.588 2.974 5.552 2.026
> ddply(iris, "Species",summarise,N=length(Sepal.Length),mean=mean(Sepal.Length),sd=sd(Sepal.Length))
Species N mean sd
Species N mean sd
1 setosa 50 5.006 0.3524897
2 versicolor 50 5.936 0.5161711
3 virginica 50 6.588 0.6358796
SUMMARYBY
La función «summaryBy» del paquete «doBy» nos permite calcular resúmenes estadísticos por grupo utilizando un formato de fórmula.
> summaryBy(Sepal.Length + Sepal.Width + Petal.Length + Petal.Width ~ Species, data=iris, FUN=mean) Species Sepal.Length.mean Sepal.Width.mean Petal.Length.mean 1 setosa 5.006 3.428 1.462 2 versicolor 5.936 2.770 4.260 3 virginica 6.588 2.974 5.552 Petal.Width.mean 1 0.246 2 1.326 3 2.026 > summaryBy(Sepal.Length ~ Species, data=iris, FUN=c(mean,sd)) Species Sepal.Length.mean Sepal.Length.sd 1 setosa 5.006 0.3524897 2 versicolor 5.936 0.5161711 3 virginica 6.588 0.6358796
También existe:
- summarize() en el paquete Hmisc
Espero que estos atajos para los cálculos te hayan gustado y te ahorren mucho tiempo, saludos!
Rosana Ferrero
 Ciencia de datos
Ciencia de datosMáster en Estadística Aplicada para Data Science con R Software
CONVOCATORIA ABIERTA | INICIO ABRIL 2024 > Logra la máxima precisión y rigor en tus proyectos de Ciencia de Datos.
Precio ConsultarDuración 10 meses – 66 ECTS
 Ciencia de datos
Ciencia de datosMáster en Machine Learning con R
CONVOCATORIA ABIERTA | INICIO ABRIL 2024 > Automatiza procesos y crea tus propios algoritmos de Machine Learning.
Precio CONSULTARDuración 10 meses – 66 ECTS
0 comentarios
Nadie ha publicado ningún comentario aún. ¡Se tu la primera persona!