¡Transforma tus datos con el paquete dplyr de R! Una buena exploración de los datos incluye su manipulación, limpieza y resumen.
"Los científicos de datos dedican del 50 al 80 % de su tiempo a la tarea mundana de recopilar, manipular y preparar datos, antes de que puedan explorarse para obtener información útil." - NYTimes (2014).
Y es que aprender a _manipular, limpiar y resumir_detectar y corregir información incorrecta, incompleta, imprecisa o innecesaria tus datos te permitirá . Son pasos previos indispensables para conocer tus datos y proponer modelos que expliquen su comportamiento.
Por esta razón, es fundamental que te familiarices con estos procesos y con las herramientas que te permitan optimizar el camino. Y justo de esto último te voy a hablar hoy.
Conoce el paquete dplyr, la herramienta estrella para la manipulación de datos en R Software.
El paquete dplyr es uno de los paquetes más poderosos y populares en R. Este paquete fue escrito por el programador de R más popular, Hadley Wickham, quien ha escrito muchos paquetes R útiles que se encuentran agrupados en la filosofía tidyverse.
En este post te guiaré para seleccionar, filtrar, organizar, cambiar (mutar), resumir y agrupar tus conjuntos de datos con uno de los paquetes más populares del Software R. Ahorra tiempo y evita errores con esta súper-herramienta que utilizarás en todos tus proyectos de datos.
Ah, además, ¡Diviértete con un ejemplo de análisis con los datos de Star Wars!
Esta publicación incluye varios consejos sobre cómo usar el paquete dplyr para limpiar y transformar datos.
Contenidos
- ¿Qué es dplyr?
- ¿Qué tiene de especial dplyr?
- Aplicación de las funciones más importantes de dplyr con datos de star wars
- Algunos tips finales para la manipulación de datos
- ?¿Quieres más? Lecturas recomendadas
¿Qué es dplyr?
El paquete dplyr (de tidyverse) nace en 2014 y trata de proporcionar herramientas fáciles para las tareas de exploración y manipulación de datos más comunes en R.
Utiliza una gramática de manipulación de datos, que proporciona un conjunto consistente de verbos que lo ayudan a resolver los desafíos más comunes de manipulación de datos:
- mutate() agrega/cambia/calcula nuevas variables (columnas).
- select() selecciona, elige variables (columnas) en función de sus nombres
- filter() filtra, elige observaciones (filas) en función de sus valores
- summarise() resume, reducir varios valores a un solo valor de resumen
- arrange() ordena, cambia el orden de las filas en función de sus valores
- group_by() agrupa, realiza operaciones de datos en grupos definidos por variables
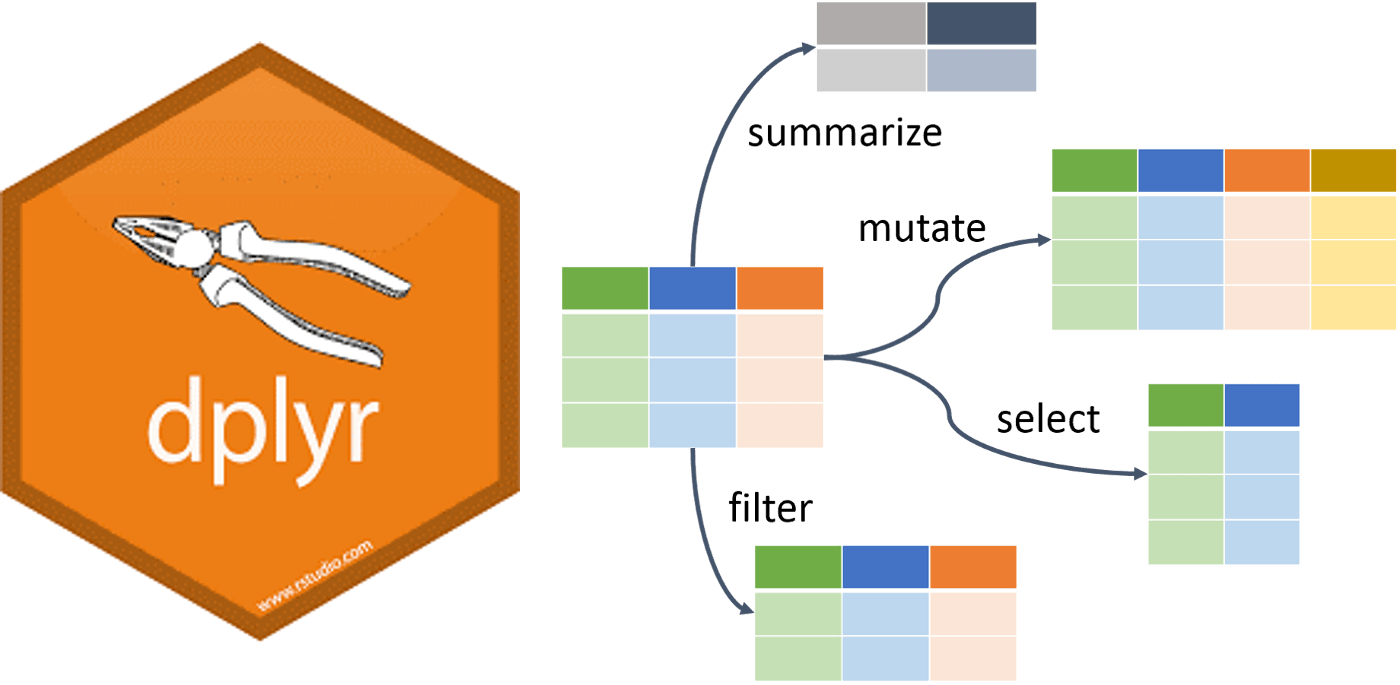
Todos los verbos funcionan de manera similar (Wickham & Grolemund, 2017):
- El primer argumento es un conjunto de datos (data frame).
- Los argumentos posteriores describen qué hacer con el data frame, utilizando los nombres de las variables (sin comillas).
- El resultado es un nuevo data frame.
En conjunto, estas propiedades hacen que sea fácil encadenar múltiples pasostuberías %>%Las tuberías ayudan a hacer que R sea expresivo, como un lenguaje hablado simples para lograr un resultado complejo. Para concatenar o unir estas funciones hemos utilizado las que están disponibles a través del paquete magrittr instalado como parte de dplyr. :
"Los idiomas hablados consisten en palabras simples que combinas en oraciones para crear pensamientos sofisticados" (Wickham & Grolemund 2014).
Lee las tuberías como "entonces" o "luego". Por ejemplo: "tome el conjunto de datos mtcars, luego agrupa los coches por tipo de transmisión, luego calcula la media del consumo de gasolina".
NO TE CONFUNDAS: ggplot utiliza el símbolo de "+" en lugar de "%>%" para agregar capas a los gráficos.
¿Qué tiene de especial dplyr?
- Comprende muchas funciones que realizan operaciones comunes de manipulación de datos, como aplicar filtros, seleccionar columnas específicas, ordenar datos, agregar o eliminar columnas y resumir datos.
- Es muy fácil de aprender y usarfácil recordar. También es estas funciones. Por ejemplo, filter() se usa para filtrar filas, como indica su nombre.
- Las funciones dplyr se procesan más rápido que las funciones base R. Esto se debe a que las funciones dplyr se escribieron de manera computacionalmente eficiente. También son más estables en la sintaxis y admiten mejor los conjuntos de datos.
- Usa el mismo lenguaje que otros paquetes tidyverse, como ggplot2, lo cual nos facilitará mucho su uso.
Aplicación de las funciones más importantes de dplyr con datos de star wars
Como ejemplo de aplicación de dplyr vamos a estudiar los personajes de la Guerra de las Galaxias. Los datos originales, de SWAPI, la API de Star Wars, https://swapi.dev/, se han revisado para reflejar investigaciones adicionales sobre las determinaciones de género y sexo de los personajes.

Activamos los paquetes y observamos los datos
> library(dplyr)
> library(tidyr)
> data(starwars)
> starwars

El conjunto de datos starwars viene incorporado en el paquete dplyr y corresponde a un conjunto de datos (un tibble) con 87 filas y 14 variables:
- name: Nombre del personaje
- height: Altura (cm)
- mass: Peso (kg)
- hair_color,skin_color,eye_color: Color de cabello, piel y ojos
- birth_year: Año de nacimiento (ABY = Antes de la Batalla de Yavin)
- sex: El sexo biológico del personaje, es decir, masculino, femenino, hermafrodita o ninguno (como en el caso de los droides).
- gender: El rol de género o la identidad de género del personaje según lo determinado por su personalidad o la forma en que fueron programados (como en el caso de los droides).
- homeworld: Nombre del mundo natal
- species: Nombre de la especie
- films: Lista de películas en las que apareció el personaje
- vehicles: Lista de vehículos que ha pilotado el personaje
- starships: Lista de naves estelares que el personaje ha pilotado
Función filter(): ¿Qué especies son androides?
Imagina que queremos quedarnos tan solo con los datos de androides, deberíamos filtrar los casos (filas) por la categoría "Droid" y para ello utilizamos la función filter() así:
> starwars %>%
filter(species == "Droid")
> # A tibble: 6 × 14
> name height mass hair_color skin_color eye_color birth_year sex gender
> 1 C-3PO 167 75 gold yellow 112 none masculi…
> 2 R2-D2 96 32 white, blue red 33 none masculi…
> 3 R5-D4 97 32 white, red red NA none masculi…
> 4 IG-88 200 140 none metal red 15 none masculi…
> 5 R4-P17 96 NA none silver, red red, blue NA none feminine
> # … with 1 more row, and 5 more variables: homeworld , species ,
> # films , vehicles , starships
Función select(): ¿de qué color son los personales?
Vamos a seleccionar aquellas variables que indican el color del personaje.
> starwars %>%
select(name, ends_with("color"))
> # A tibble: 87 × 4
> name hair_color skin_color eye_color
> 1 Luke Skywalker blond fair blue
> 2 C-3PO gold yellow
> 3 R2-D2 white, blue red
> 4 Darth Vader none white yellow
> 5 Leia Organa brown light brown
> # … with 82 more rows
Función mutate(): ¿Qué personajes están en forma?
Para responder a esta pregunta primero podríamos calcular el índice de masa corporal (BMI) con la fórmula bmi = mass / ((height / 100) ^ 2).
> starwars %>%
mutate(name, bmi = mass / ((height / 100) ^ 2)) %>%
select(name:mass, bmi)
> # A tibble: 87 × 4
> name height mass bmi
> 1 Luke Skywalker 172 77 26.0
> 2 C-3PO 167 75 26.9
> 3 R2-D2 96 32 34.7
> 4 Darth Vader 202 136 33.3
> 5 Leia Organa 150 49 21.8
> # … with 82 more rowsCon esta información podríamos quedarnos tan solo con los casos cuyo bmi se encuentre entre 18.5-24.9.
> starwars %>%
mutate(name, bmi = mass / ((height / 100) ^ 2)) %>%
select(name:mass, bmi) %>%
filter( between(bmi, 18.5, 24.9))
> A tibble: 24 × 4
> name height mass bmi
> 1 Leia Organa 150 49 21.8
> 2 Obi-Wan Kenobi 182 77 23.2
> 3 Anakin Skywalker 188 84 23.8
> 4 Chewbacca 228 112 21.5
> 5 Han Solo 180 80 24.7
> 6 Greedo 173 74 24.7
> 7 Boba Fett 183 78.2 23.4
> 8 Qui-Gon Jinn 193 89 23.9
> 9 Nute Gunray 191 90 24.7
> 10 Ben Quadinaros 163 65 24.5
> … with 14 more rows¡Leia y Anakin están en forma!?
Función arrange(): ¿Cuál es el personaje más pequeño (menos pesado)?
> starwars %>%
arrange(asc(mass))
> A tibble: 87 × 14
> name height mass hair_color skin_color eye_color birth_year sex gender
> 1 Ratts T… 79 15 none grey, blue unknown NA male mascu…
> 2 Yoda 66 17 white green brown 896 male mascu…
> 3 Wicket … 88 20 brown brown brown 8 male mascu…
> 4 R2-D2 96 32 NA white, bl… red 33 none mascu…
> 5 R5-D4 97 32 NA white, red red NA none mascu…
> 6 Sebulba 112 40 none grey, red orange NA male mascu…
> 7 Dud Bolt 94 45 none blue, grey yellow NA male mascu…
> 8 Padmé A… 165 45 brown light brown 46 fema… femin…
> 9 Wat Tam… 193 48 none green, gr… unknown NA male mascu…
> 10 Sly Moo… 178 48 none pale white NA NA NA
> … with 77 more rows, and 5 more variables: homeworld , species ,
> films , vehicles , starshipsY aquí vemos en segundo lugar al pequeño Yoda.

Funciones summarise() y group(): ¿Cuál es el peso medio por especie?
Imagina que ahora quieres describir las especies, por ejemplo por su peso medio, y quedarte con aquellas especies con más de 50kg (y más de 1 caso o sujeto).
> starwars %>%
group_by(species) %>%
summarise(
n = n(),
mass = mean(mass, na.rm = TRUE)
) %>%
filter(
n > 1,
mass > 50
)
> # A tibble: 8 × 3
> species n mass
> 1 Droid 6 69.8
> 2 Gungan 3 74
> 3 Human 35 82.8
> 4 Kaminoan 2 88
> 5 Mirialan 2 53.1
> # … with 3 more rowsVemos, por ejemplo, que los androides pesan en promedio caso 70kg, mientras que los humanos 82.8.
Algunos tips finales para la manipulación de datos
- Valores perdidos. Afortunadamente, todas las funciones de agregación tienen un argumento na.rm que elimina los valores faltantes antes del cálculo.
- Recuentos. Siempre que realices una agregación es una buena idea incluir un recuento (n()) o un recuento de valores no faltantes ( sum(!is.na(x))). De esa manera, puedes comprobar que no estás sacando conclusiones basadas en cantidades muy pequeñas de datos.
- Desagrupación. Si necesitas eliminar la agrupación y volver a las operaciones con datos desagrupados, usa ungroup().
Espero este post te sea de gran utilidad, un saludo?
Puedes descargar la guía rápida de funciones del paquete dplyr (en inglés o español) en este enlace.

?¿Quieres más? Lecturas recomendadas
- Introduction to dplyr: https://cran.r-project.org/web/packag...
- Conferencias de Jenny Bryan de STAT545 en UBC: Introducción a dplyr
- Hadley Wickham y Garrett Grolemund's R for Data Science
- Software R de Carpentry para materiales de análisis científicos reproducibles: manipulación de marcos de datos con dplyr
- Desarrollado por primera vez para Carpintería de software en UCSB
- Hoja de trucos de disputa de datos de RStudio
- Seminario web de discusión de datos de RStudio
- Historia de los operadores de tubería.
- Funciones de anidamiento versus tuberías
- Cuándo no usar la tubería.
- data.table vs dplyr: ¿puede uno hacer algo bien y el otro no puede o lo hace mal?