
Hola,
He dividido esta Guía para describir tus datos en 3 pasos (o 3 post).
Hoy veremos el segundo paso:
PASO 1. PREPARA TUS DATOS PARA EL ANÁLISIS
PASO 2. ELIGE LA MEJOR HERRAMIENTA
GRÁFICOS • Un gráfico todo en uno • Gráfico de barras para variables categóricas …….• Gráfico de barras para 2 variables • Histograma para variables numéricas • Diagrama de cajas para variables numéricas …….• Cómo interpretar el Diagrama de cajas …….• Cómo interpretar la simetría de nuestros datos …….• Cómo combinar varias variables en un solo gráfico
TABLAS DE FRECUENCIA • Tablas simples • Tablas de contingencia
RESUMEN NUMÉRICO • Estadísticos de Tendencia central, de Dispersión o variabilidad, de Posición y de forma • Descripción básica • Descripción detallada • Descripción por grupo
PASO 3. COMUNICA TUS RESULTADOS EN FORMATO APA
ELIGE LA MEJOR HERRAMIENTA
El siguiente paso es seleccionar adecuadamente la herramienta para describir nuestros datos.
Existen 3 tipos de herramientas descriptivas:
- GRÁFICOS.
- TABLAS DE FRECUENCIA.
- RESUMEN NUMÉRICO.
Tal vez la más importante, porque es la que nos suele dar mayor información, son los gráficos. Una imagen vale más que mil palabras, dicen. Y según el tipo de variable, vamos a elegir el gráfico más adecuado para describirla.
Cuando tenemos variables categóricas o factores, nos interesará crear tablas de frecuencia donde tengamos el conteo o el porcentaje de casos para cada categoría de nuestra variable.
Y finalmente tenemos el resumen numérico mediante estadísticos descriptivos como la media o la varianza. También veremos cuando utilizar cada tipo de resumen y cómo interpretarlos.
Video como realizar gráficos en R enlace
Realizar gráficos elegantes R
Veamos ahora los gráficos que podemos crear según el tipo de variable que tenemos.
- Variables categóricas:
- Diagrama de barras
- Diagrama de sectores
- Variables numéricas:
- Histograma
- Diagrama de cajas
Para representar variables categóricas podemos utilizar el diagrama de barras o el de sectores (que aquí no veremos porque da muy poca información), donde se observa la frecuencia (absoluta o relativa) de cada categoría en forma de barras o en un diagrama circular, respectivamente. El gráfico de sectores no lo veremos en este post.
Para variables numéricas tenemos histogramas para representar la frecuencia (absoluta o relativa) de intervalos de la variable o el diagramas de cajas que representa la distribución de los datos indicando valores como la mediana y los cuartiles.
Y, por supuesto, podemos obtener más tipos de gráficos si queremos representar gráficamente más de 1 variable a la vez, por ejemplo, para 2 variables numéricas podemos realizar un diagrama de dispersión.
Un gráfico todo en uno
La manera más sencilla de obtener un gráfico de nuestros datos es con la función ggpairs() del paquete GGally que utiliza la filosofía ggplot. Aquí la función reconoce el tipo de variable que le ingresamos y selecciona automáticamente el gráfico adecuado. También le podemos indicar si queremos que coloree los gráficos a partir de una variable categórica que tenemos.

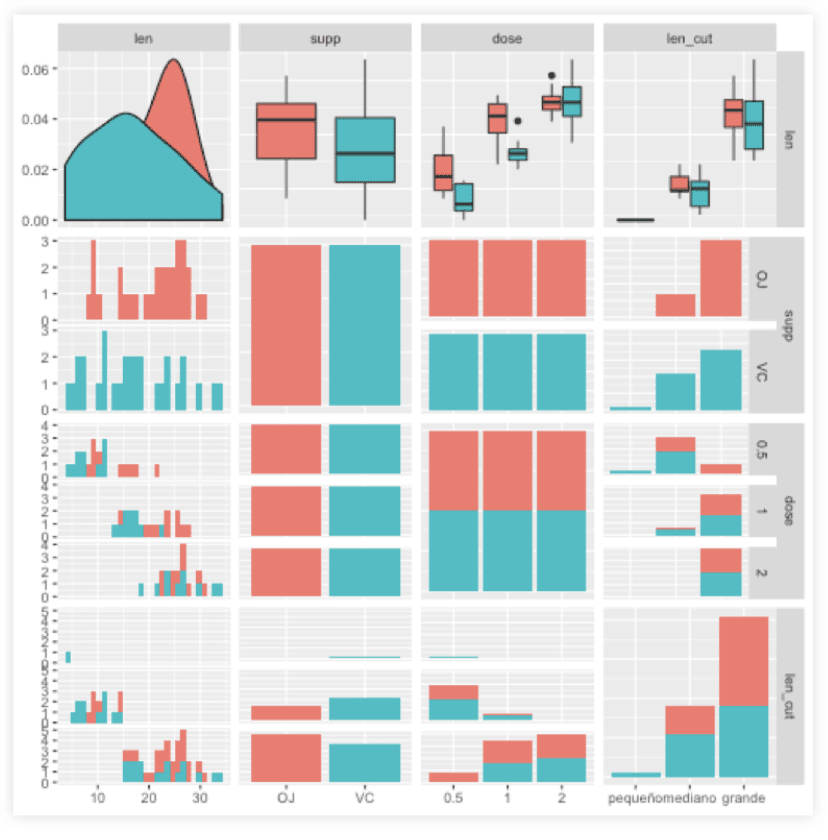
En este caso le he dicho que utilice la variable suplemento de vitamina C para colorear el gráfico, tenemos en rojo el jugo de naranja y en verde el ácido absórbico.
Vemos que con la variable len, primera columna, se ha realizado varios histogramas en función de las demás variables categóricas.
La segunda columna tiene información de la variable supp, la tercera de la variable dose y la última corresponde a las categorías de largo de dientes, para las cuales se utilizaron diagramas de barras.
En la primer fila donde se cruza 1 variable numérica len y 1 variable categórica, obtenemos diagramas de cajas por grupo. Estos son los gráficos más interesantes y los voy a interpretar más adelante.
VARIABLES CATEGÓRICAS: GRÁFICO DE BARRAS
Utilizamos la función ggplot indicándole el nombre de los datos y la variable que queremos graficar, seguido por el tipo de gráfico que queremos, el diagrama de barras.
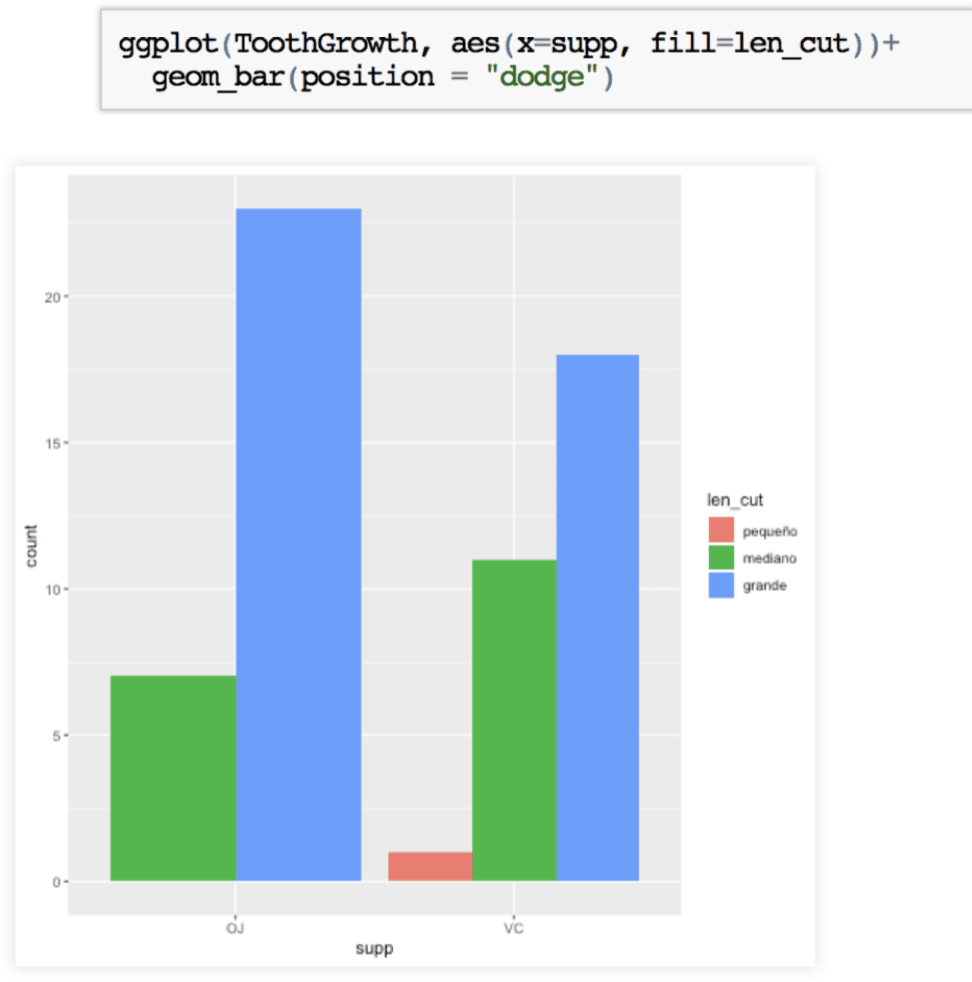
El Gráfico de barras para la variable supp nos indica que tenemos 30 conejillos en cada tratamiento de vitamina C.

Gráfico de barras para 2 variables
Podemos agregar más información al diagrama anterior si incluimos la variable categorías de largo de dientes. Para ello le indicamos que coloree o rellene las barras según la información de la variable len_cut.
Vemos aquí, nuevamente, que el único caso de dientes pequeños corresponde al tratamiento con ácido absórbico, pero que este grupo también tiene menor número de casos de conejillos con dientes grandes.
VARIABLES NUMÉRICAS: HISTOGRAMAS
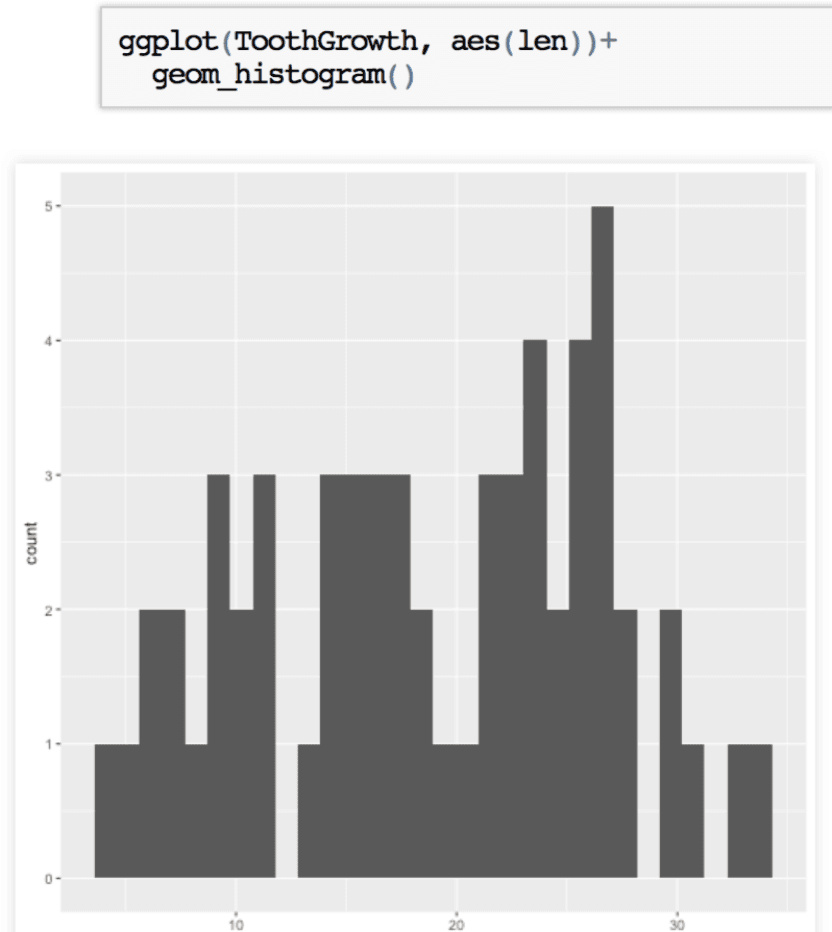
Luego tenemos los histogramas para variables numéricas. Nos permite observar la distribución de los datos, el eje x tiene la escala de valores de la variable que estamos analizando, aquí el largo de dientes, mientras que el eje “y” tiene el conteo de casos para cada intervalo del histograma.
Basta con indicar el tipo de gráfico geom_hist para representar el histograma.
Aquí vemos que la distribución no es simétrica, sino que hay un pico de casos de dientes largos cerca de los 25mm.
VARIABLES NUMÉRICAS: DIAGRAMA DE CAJAS
Por último tenemos el diagrama de cajas para variables numéricas, que ya les comenté es el más informativo y vamos a detallar.
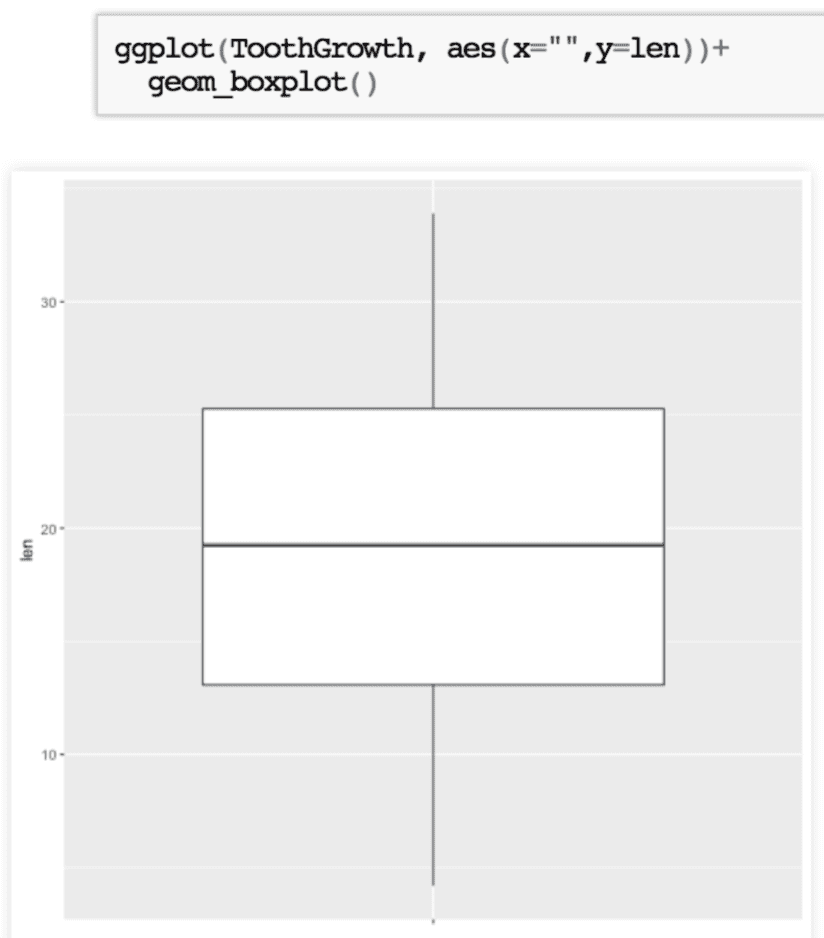
Aquí utilizaremos la función geom_boxplot para indicarle que queremos graficar cajas.
Si solo incluimos una variable (len) en el eje “x” tenemos 1 única indicación, y una única caja. En el eje “y” tenemos los valores ordenados de largo de dientes.
Cómo interpretar el Diagrama de cajas
En el siguiente esquema les muestro cómo interpretar cada información del gráfico
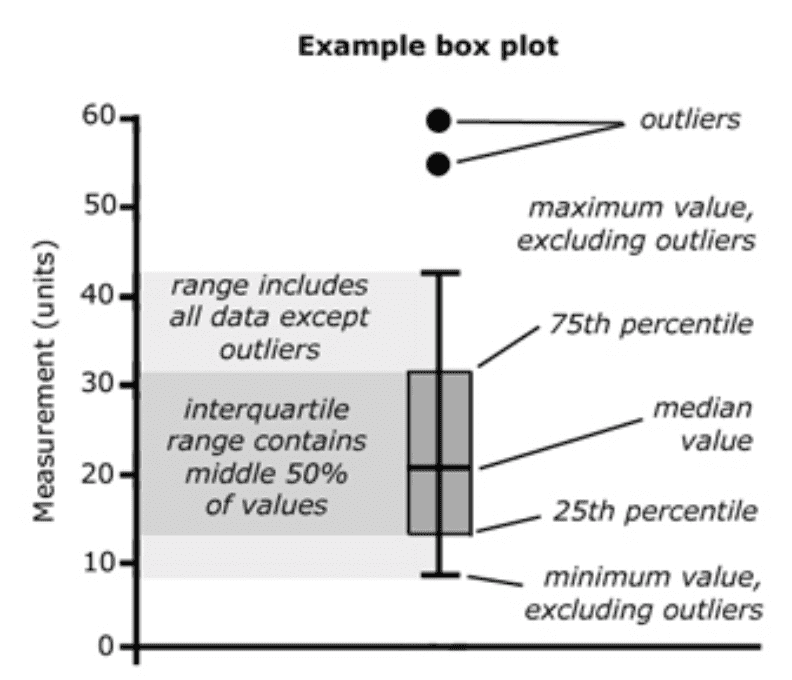
La línea central corresponde a la mediana de los datos, mientras que la caja engloba el 50% de los valores centrales de los datos. Cuanto mayor sea la caja mayor variabilidad en los datos.
Luego tenemos los “bigotes” que van desde el menor al mayor valor, excluyendo los valores atípicos u outliers. Los bigotes del gráfico nos permiten describir si los datos son simétricos o no, según los bigotes sean del mismo largo o no, respectivamente.
Los outliers son valores que se comportan distinto al resto y se indican mediante puntos y tendremos que tener cuidado con ellos porque pueden perturbar los resultados de nuestros análisis. Debemos revisar estos valores para asegurarnos de que no sean erratas en la base de datos y en caso de que sean valores genuinos podemos intentar disminuir su influencia en los resultados por ejemplo, seleccionando un estadístico como la mediana en lugar de la media para representar la tendencia central de los datos.¡
Puedes leer más sobre outliers en nuestro post:
Cómo lidiar con los datos atípicos
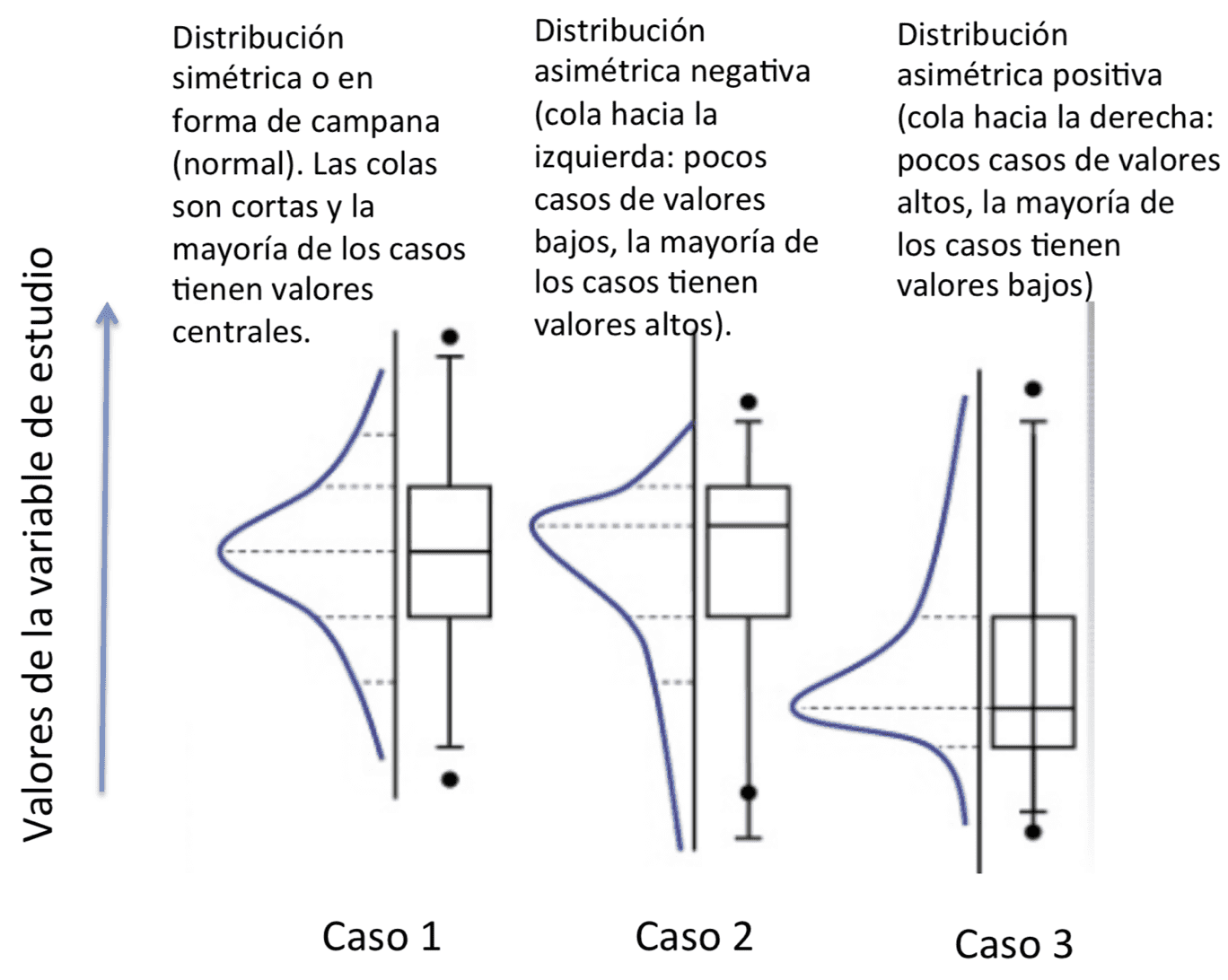
Cómo interpretar la simetría de nuestros datos
En este gráfico se observa la correspondencia entre la simetría de la distribución de los datos y el gráfico de cajas. Si los bigotes son cortos y simétricos, diremos que la distribución es simétrica.
Cómo combinar varias variables en un solo gráfico
Ahora, podemos combinar una variable numérica y una categórica en un diagrama de cajas. Esto nos permitirá comparar la mediana, la variabilidad y la presencia de outliers entre distintos grupos.

¿Qué por qué es tan importante realizar un buen gráfico con tus datos? Visita nuestro post:
POST Errores comunes que puedes evitar con un simple gráfico
TABLAS DE FRECUENCIA
Tablas de frecuencia simple
Si tienes solo 1 variable categórica puedes utilizar la función table() para obtener una tabla de frecuencia
Por ejemplo, podemos observar el número de casos u observaciones que tenemos para cada tipo de suplemento de vitamina C. Aquí tenemos 30 observaciones para cada tipo de tratamiento.

Tablas de contingencias
Pero más interesante es obtener tablas de contingencia o de doble entrada para 2 variables categóricas. La manera más sencilla de obtener las frecuencias absolutas (conteo) y relativa (porcentaje) para la relación entre 2 variables categóricas, es mediante la función CrossTable. El resultado es una tabla de contingencia o doble entrada donde se muestra la siguiente información.
En este caso vemos que solo existe 1 caso de dientes pequeños para un conejillo al que se le suministró vitamina C mediante ácido absórbico. Vemos, por ejemplo, que al 56,1% de los conejillos con dientes grandes se les suministró jugo de naranja y al 43.9% restante el ácido absórbico.


RESUMEN NUMÉRICO
Y llegamos ya al resumen numérico de los datos.
Podemos dividir el resumen estadístico principalmente en medidas de:
- Tendencia central (e.g. la media y la mediana)
- Dispersión o variabilidad (e.g. la desviación estándar, la varianza, el rango intercuartílico)
- Posición (e.g. los cuartiles)
- Forma (e.g. coeficiente de asimetría, coeficiente de curtosis o apuntamiento)
¿Cómo podemos obtener estos valores? Veamos las principales funciones que tiene R.
DESCRIPCIÓN BÁSICA
La descripción más sencilla la obtenemos con la función summary() que reconoce automáticamente el tipo de variable que ingresamos. Si se trata de una variable categórica nos muestra el conteo para cada categoría, mientras que si la variable es numérica nos indica el valor mínimo, primer cuartil, mediana, media, tercer cuartil y valor máximo.
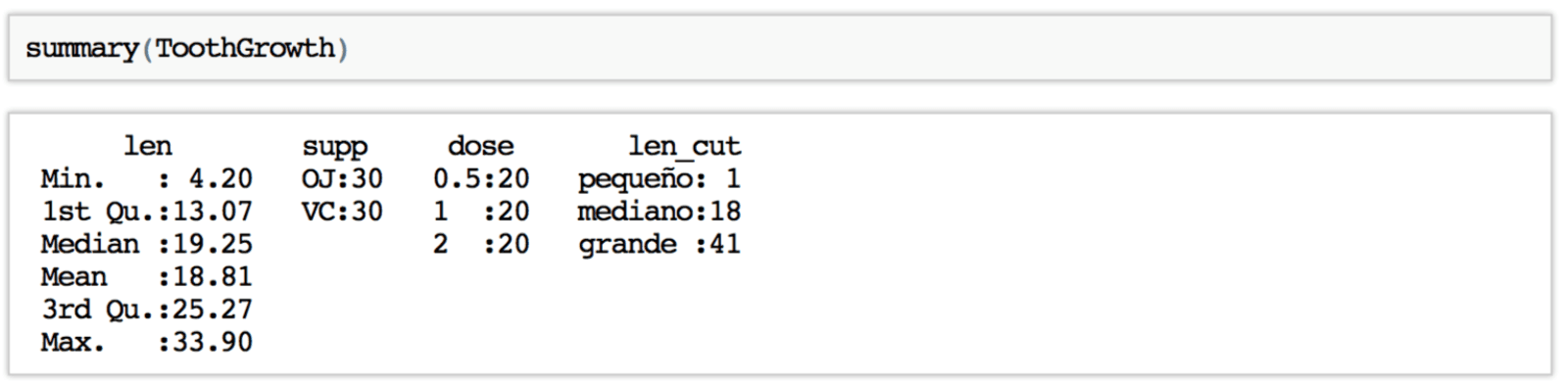
También, si existieran valores ausentes se indicaría su conteo mediante una categoría NA para cada variable.
DESCRIPCIÓN DETALLADA
Podemos obtener una descripción más detallada con la función describe() del paquete Hmisc.
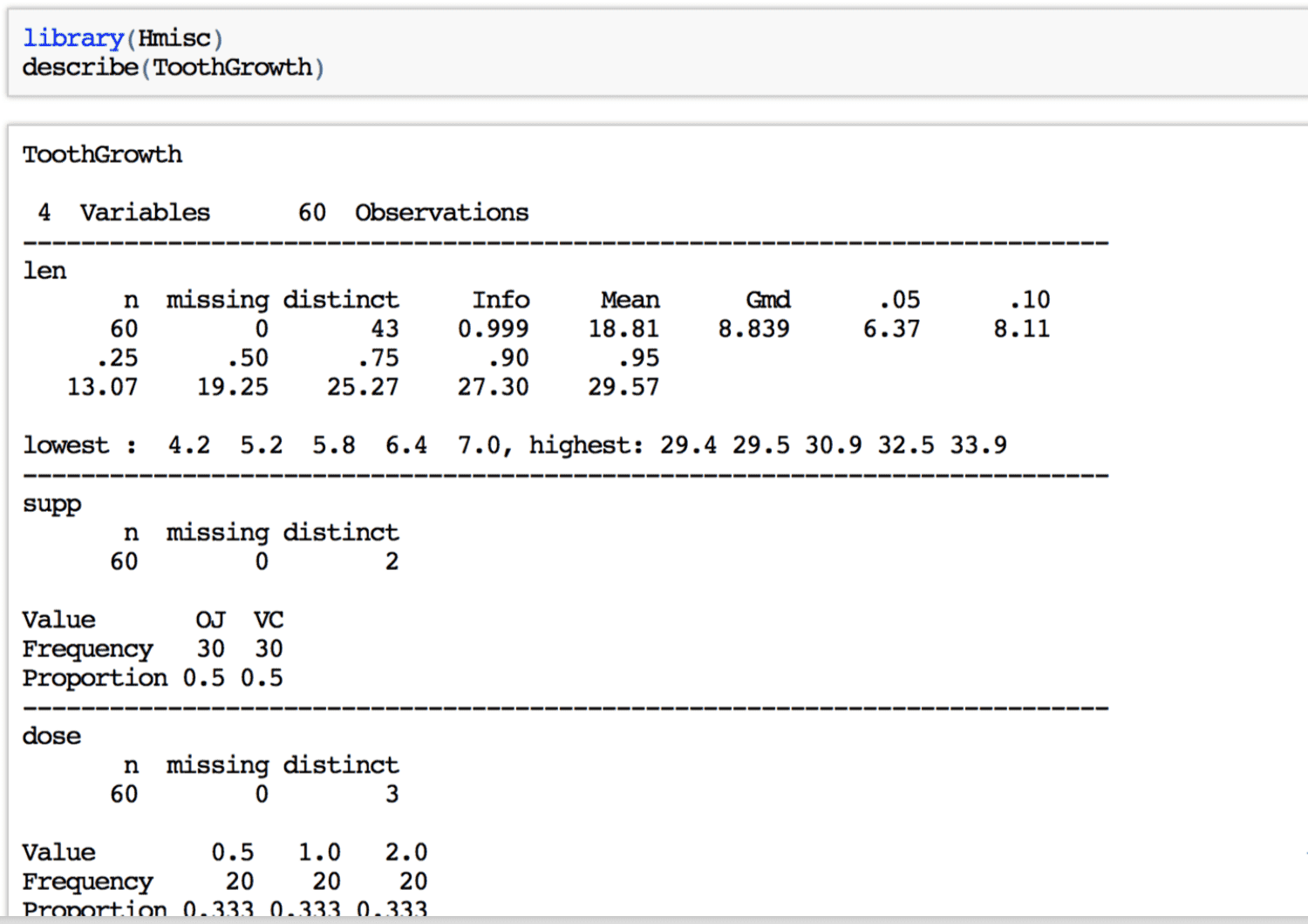
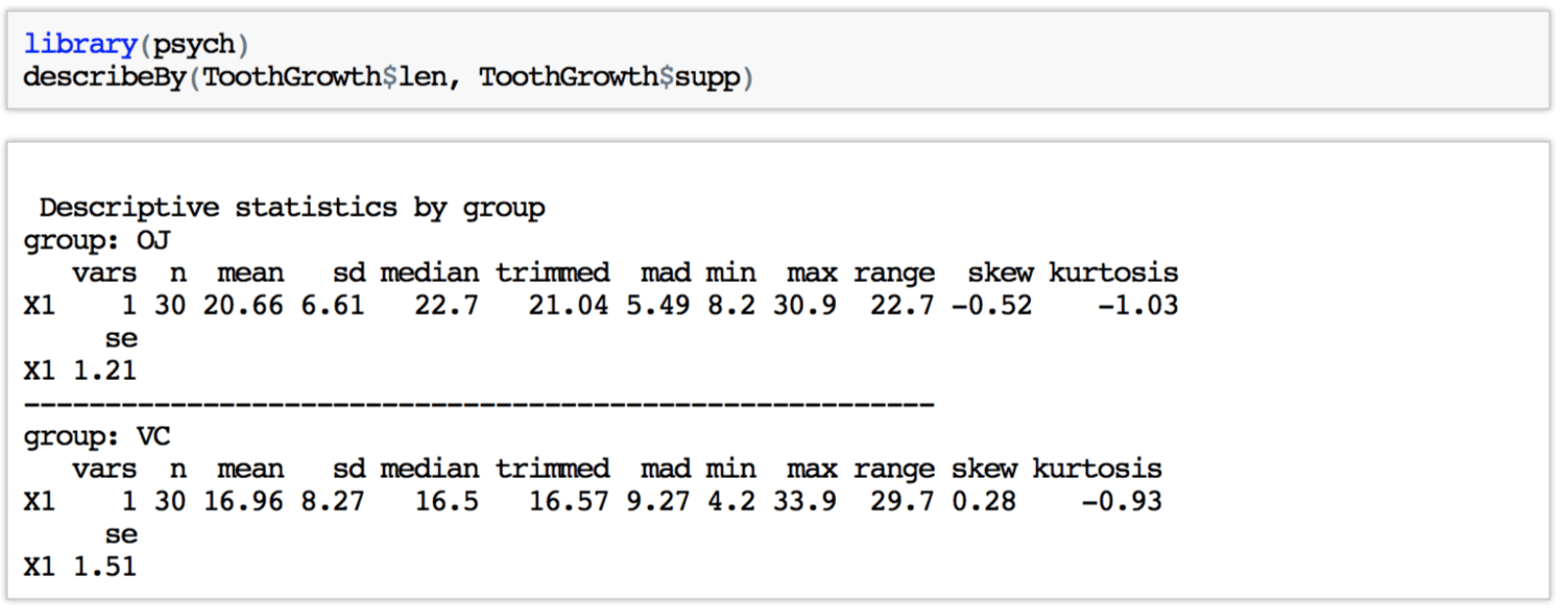
DESCRIPCIÓN POR GRUPO
O incluso describir una variable numérica como len según una variable categórica como supp. En este caso vemos el resumen descriptivo del largo de los dientes para cada grupo de tratamiento.
Vemos que se calculan estadísticos como la desviación estándar (sd), una versión robusta de la media (trimmed o media recortada), la asimetría (skew) y la curtosis.
Y como hay mil caminos que conducen a Roma, tienes otras opciones en nuestro post:
Cómo calcular resúmenes por grupo rápidamente
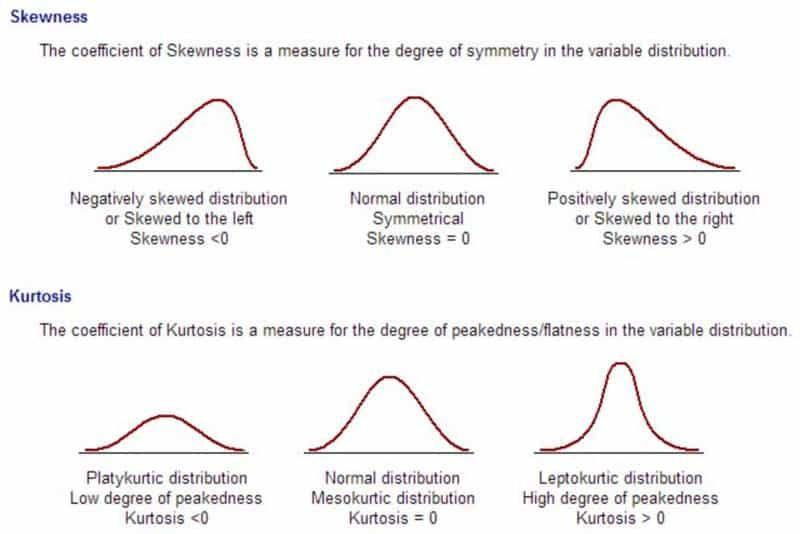
Cómo interpretar la asimetría y la curtosis
Para interpretar la asimetría y curtosis puedes valerte del siguiente gráfico.
La asimetría nos permite ver si existe más casos con valores altos o bajos, por ejemplo.. Si la distribución es simétrica tendremos una distribución similar a una normal, que es un requisito para varias pruebas de hipótesis, el siguiente paso en un análisis.
La curtoris nos indica qué tan puntiaguda es la distribución, por ejemplo, si la distribución es aplanada o platicúrtica tendremos muchos casos con valores en los extremos de la distribución o colas, mientras que si tenemos una distribución leptocúrtica las colas serán cortas.
RESUMIENDO QUE ES GERUNDIO
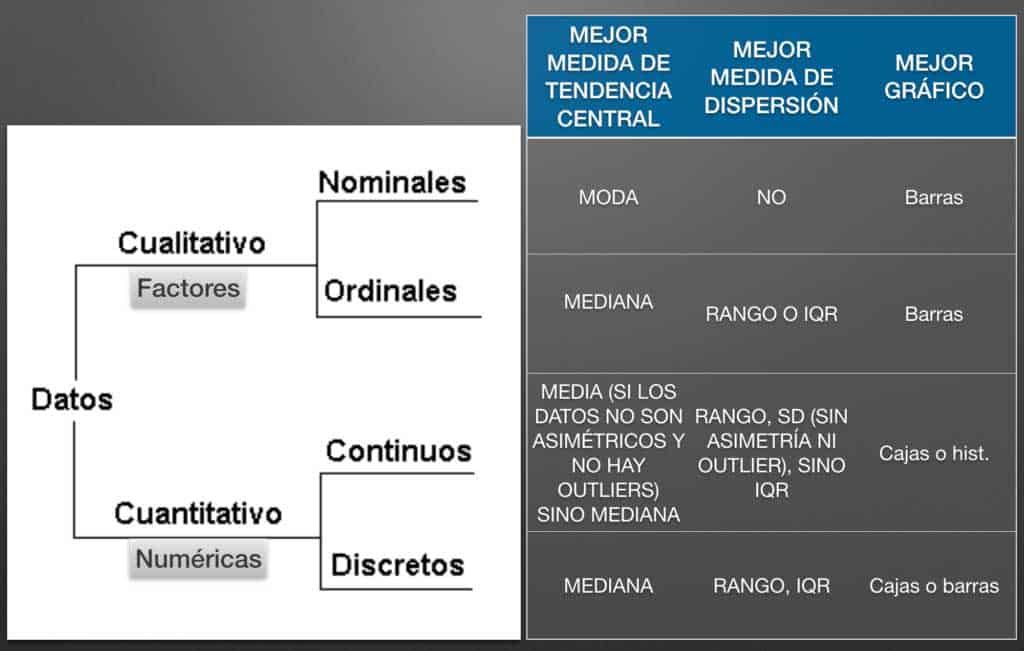
El siguiente esquema resume la mejor manera de describir cada tipo de variable
- Por ejemplo, en cuanto a la centralidad de los datos, si tenemos una variable categórica o factor como el sexo, no tiene sentido calcular la media sino que utilizaremos la moda que nos dice la categoría con mayor frecuencia. Para variables numéricas podemos utilizar la media si los datos son simétricos y no contienen outliers, o la mediana en caso contrario.
- Si queremos medir la variabilidad de los datos, utilizaremos la desviación estándar (SD) o el rango intercuartílico (IQR) que es mejor ante la la presencia de outliers.
- En cuanto a los gráficos, recordemos que tenemos los diagramas de barras para variables categóricas o factores, y diagramas de cajas para variables numéricas.
También puedes descargar nuestra chuleta sobre estadística descriptiva con R, validada por RStudio.
Guía Rápida de Estadística Descriptiva con R
¡Espero que esta guía te sea de gran utilidad!
¡Saludos!


