
¿Qué es un dato atípico o outlier?
Un dato atípico o outlier es una observación que se aleja considerablemente del resto de datos en un conjunto. Estos valores pueden tener un gran impacto en el análisis estadístico, especialmente si se utilizan medidas sensibles a su presencia, como la media aritmética. Por ello, identificar y gestionar adecuadamente estos datos es fundamental para obtener conclusiones fiables.
La media y su sensibilidad a los outliers
Si te preguntan qué medida describe mejor un conjunto de datos, probablemente responderás: la media. Sin embargo, ¿es siempre la mejor opción? Para ilustrarlo, supongamos el siguiente conjunto:
10, 10, 11, 12, 12, 13, 14, 15, 15, 15, 16, 18, 19
La media es 13.85 aproximadamente. Ahora cambiemos el último valor por un número extremo:
10, 10, 11, 12, 12, 13, 14, 15, 15, 15, 16, 18, 200
La nueva media sube drásticamente a 27.77. Esto demuestra que un solo valor extremo puede influir enormemente en la media, haciendo que deje de ser representativa del conjunto.
¿Por qué es importante la robustez en los estimadores?
La robustez se refiere a la capacidad de un estimador para no ser afectado por valores extremos o atípicos. En el caso de la media, la falta de robustez hace que los outliers "pesen más" y distorsionen la interpretación de los datos. Por ello, para conjuntos con datos atípicos, es preferible usar medidas robustas que minimicen esta influencia.
Soluciones para los datos atípicos
No eliminar los outliers sin razón
Eliminar un dato atípico solo es justificable si se trata de un error de medición o de construcción de la base de datos. Si el valor extremo es real, eliminarlo puede introducir sesgos, reducir el tamaño de la muestra y afectar la distribución y la varianza. La variabilidad en los datos, incluso la provocada por outliers, es fundamental para entender el fenómeno estudiado.
Técnicas para disminuir el impacto de los outliers
En lugar de eliminar outliers, es mejor reducir su peso en el análisis. Esto se logra mediante técnicas robustas que son menos sensibles a valores extremos y ofrecen estimaciones más fiables. Estas técnicas incluyen métodos estadísticos robustos modernos, que mantienen la esencia de los métodos clásicos pero son más resistentes a desviaciones.
Alternativas robustas a la media
La mediana
La mediana es el valor central en un conjunto ordenado y es mucho más robusta que la media frente a outliers. En el ejemplo anterior, la mediana se mantiene en 14, incluso con el valor extremo de 200.
Media recortada (trimming)
La media recortada elimina un porcentaje fijo de los datos más extremos antes de calcular la media. Por ejemplo, si recortamos un 20% de valores extremos en el conjunto modificado, la media recortada es 13.67, mucho más cercana al valor original que la media aritmética.
Media winsorizada
La media winsorizada reemplaza un porcentaje de los valores extremos con los valores más cercanos dentro del rango intermedio, suavizando la influencia de los outliers. En nuestro caso, la media winsorizada es 13.62, similar a la media recortada.

Impacto de los outliers en la inferencia estadística
Los datos atípicos afectan no solo la estadística descriptiva, sino también la inferencial. Las pruebas de hipótesis, correlaciones y regresiones pueden dar resultados erróneos si se violan los supuestos por la presencia de outliers.
Pruebas estadísticas robustas
Las pruebas robustas ofrecen varias ventajas:
- Son estables ante pequeñas desviaciones de los supuestos clásicos (normalidad, homocedasticidad).
- Minimiza la influencia de los outliers.
- Son más potentes cuando los datos no cumplen con normalidad o igualdad de varianzas.
Por ejemplo, para comparar medias entre dos grupos, la prueba robusta de Yuen basada en medias recortadas detecta diferencias significativas donde otras pruebas no lo hacen, especialmente en presencia de outliers.
Ejemplo práctico: comparación de caballos de fuerza en coches
Imaginemos que queremos comparar dos medias. Disponemos de 32 tipos de automóviles (modelos de 1973-74) de USA (datos "mtcars" de R-software) y queremos comparar los caballos de fuerza entre los coches de transmisión automática y manual (Tabla 2). Para los coches con transmisión manual la variable caballos de fuerza no se distribuye según la normal (W = 0.76758, p-value = 0.00288) pero sí para los de transmisión automática (W = 0.95835, p-value = 0.5403), además sabemos que se trata de grupos homogéneos (F(1,30)=0.1842, p-value=0.6709).
Como la variable de estudio no se distribuye según la normal deberíamos recurrir a las pruebas no paramétricas (U de Mann-Whitney) en lugar de las paramétricas (t de Student). Sin embargo, en este caso concreto ninguna de estas dos opciones es la adecuada, debido a la presencia de datos atípicos u outliers (Figura 1).
La prueba robusta de Yuen, que utiliza las medias recortadas, es capaz de detectar diferencias significativas entre ambos grupos, ¡diferencias que las demás pruebas no fueron capaces de detectar! (Tabla 2).Tabla 2. Contrastes de hipótesis con pruebas paramétricas, no paramétricas y robustas. Utilizamos el conjunto de datos "mtcars" de R-software donde comparamos los caballos de potencias entre coches con transmisión automática y manual.
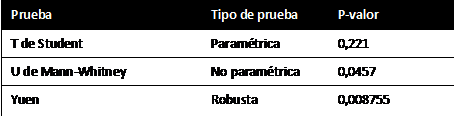
La prueba de Yuen es una alternativa a las pruebas t de Studen y U de Mann-Whitney para muestras de pequeño tamaño con distribuciones no normales y presencia de datos atípicos (outliers).
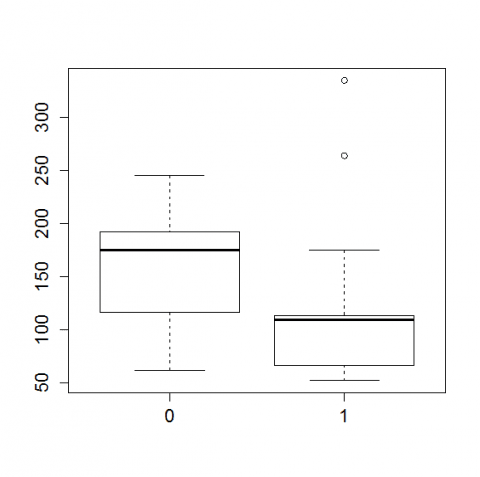
Figura 1. Diagrama de cajas para la variable caballos de fuerza de coches con transmisión automática (0) y manual (1). Se observa la presencia de valores atípicos u outliers para los coches con transmisión manual (los puntos).
Este tipo de ejemplos podría extenderse para el caso de comparaciones de más de dos medias, análisis de correlaciones, regresiones, etc..
Entonces, si los beneficios son tan importantes, ¿por qué se utilizan poco los métodos robustos?
¿Por qué no se usan más los métodos robustos?
Muchas veces, los investigadores desconocen las limitaciones de los métodos clásicos o no saben cómo aplicar técnicas robustas. Además, la mayoría de los softwares estadísticos no incluyen fácilmente estas herramientas, salvo excepciones como R.
Los métodos robustos suponen que los datos provienen de distribuciones unimodales y simétricas con algunos valores extremos. No son adecuados para distribuciones multimodales o fuertemente sesgadas, donde otros enfoques deben ser considerados.
Los métodos estadísticos robustos son una excelente alternativa para lidiar con outliers sin necesidad de eliminar datos extremos. Permiten obtener análisis más fiables y evitar interpretaciones erróneas. Tanto en estadística descriptiva como inferencial, estos métodos minimizan la influencia de valores atípicos, preservando la riqueza informativa de la variabilidad.
Y tú, ¿conocías la estadística robusta?


