
Un ejemplo práctico para comprender el ANOVA de una vía en R Software.
En la entrada anterior te hablé sobre la prueba ANOVA de una vía para un factor entre-grupos.
Si aún no lo has leído… ¡¿qué estás esperando?!
Pero hoy te traigo un ejemplo muy divertido para mostrarte cómo realizar esta prueba ANOVA en R.
Vamos a analizar los efectos del consumo de alcohol en la selección de pareja. ¿Qué te parece? ¿Crees que nos volvemos menos selectivos cuando tomamos una copa de más? ¿En qué momento el alcohol hace su efecto?
- ¿Nos volvemos menos selectivos con unas copas de más?
- ¿Cómo se realiza el ANOVA de una vía con R?
- Acceder a los datos
- Describir los datos
- Datos atípicos: comprueba que no hay valores atípicos significativos en tus datos.
- Normalidad: comprueba que la variable dependiente tiene distribución “aproximadamente" normal para cada categoría de la variable independiente.
- Homogeneidad de varianza: comprueba que las varianzas de la respuesta en cada grupo son iguales.
- ¿Existen diferencias entre los grupos?: prueba ANOVA
- ¿Entre qué grupos hay diferencias?: pruebas post hoc
- Reflexión final sobre la prueba ANOVA en R
¿Nos volvemos menos selectivos con unas copas de más?
Vamos a trabajar con los datos “googles” del paquete WRS2 para averiguar si luego de consumir alcohol las percepciones subjetivas del atractivo físico se vuelven menos rigurosas (beer goggles effect).
Los datos
Los datos corresponden a 48 participantes (24 hombres y 24 mujeres) que se han dividido en 3 grupos de 8 participantes cada uno. Cada grupo asistió a un club nocturno, a un grupo no se le dio alcohol, otro tomó 2 pintas y el último 4 pintas de alcohol. Al final de la noche el investigador tomó una fotografía a la pareja elegida por el participante y un grupo de jueces independientes evaluó el poder de atracción de dicha persona.La base de datos tiene 3 variables:
- el sexo (variable gender: hombre o mujer),
- el alcohol consumido (variable alcohol: nada, 2 pintas o 4 pintas),
- el nivel de atracción física de la pareja encontrada (variable attractiveness: puntaje de 0 a 100 dado por los jueces)
Tenemos entonces una variable dependiente numérica (attractiveness) y la queremos comparar entre tres niveles de una variable categórica (alcohol) que corresponden a muestras independientes porque son sujetos distintos. Debemos utilizar un ANOVA de una vía o un factor entre-grupos.Luego de evaluar si existen diferencias entre los grupos, y si obtenemos un resultado estadísticamente significativo (sí hay diferencias), nos interesará evaluar entre qué grupos específicamente encontramos estas diferencias. Para ello utilizaremos la prueba de comparaciones múltiples post hoc.
¿Cómo se realiza el ANOVA de una vía con R?
¡Manos a la obra!
Los primeros pasos de cualquier análisis incluyen realizar un análisis descriptivo y buscar posibles datos atípicos. Si aún no tienes claro estos conceptos te recomiendo que revises nuestras entradas sobre estos temas antes de continuar.En esta entrada vamos a probar los supuestos de los modelos lineales (normalidad, homogeneidad de varianza e independencia), a realizar el ANOVA de una vía con un factor entre-grupos (calcular el estadístico F y el valor de probabilidad asociado, p-valor) y luego la prueba de comparación múltiple post-hoc.
Acceder a los datos
Para acceder a los datos debemos primero instalar el paquete WRS2 si es que aún no la tienen instalada (utiliza install.packages("WRS2")), activarla y luego activar los datos. Si tienes problemas para instalar este paquete consulta este link para hacerlo desde Github.También vamos a calcular un resumen estadístico rápido de los datos. # install.packages("WRS2") # utilízalo si aún no tienes instalada la librería.
Describir los datos
Para las variables categóricas obtenemos la frecuencia (número de observaciones) de cada nivel, mientras que para las variables numéricas obtenemos una serie de estadísticos (Min=mínimo, 1st Qu=primer cuartil, Median=mediana, Mean=media, 3rd Qu=tercer cuartil, Max=máximo).
Veamos cómo está formada la base de datos.

Tenemos 16 observaciones por grupo (¡son pocos datos!).Calculamos los estadísticos descriptivos por grupo utilizando la función describeBy del paquete psych (pero hay varios caminos para llegar a Roma, puedes utilizar la función que más te guste). install.packages("psych") # utilízalo si aún no tienes instalada la librería.

Los dos primeros grupos presentaron valores similares en el atractivo de las parejas que encontraron, sin embargo, estos valores disminuyeron en el grupo que consumió más alcohol:
- No consume alcohol, 63.75±8.47
- 2 pintas de alcohol, 64.69±9.91
- 4 pintas de alcohol, 46.56±14.34
Los valores se presentan como media±sd (desviación estándar). Visualizamos los datos (y observamos si existen datos atípicos).
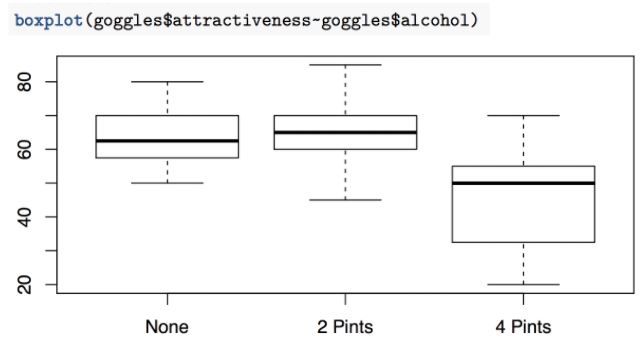
Según el gráfico de cajas y los estadísticos descriptivos, la selección de pareja según su atractivo físico disminuye para sujetos que beben mucho alcohol, pero también este comportamiento parece que se vuelve más variable.
Datos atípicos: comprueba que no hay valores atípicos significativos en tus datos.
**Los datos atípicos (outliers) pueden influir negativamente en los resultados del ANOVA.**Vamos a identificar posibles datos atípicos mediante la función rp.outlier del paquete rapportools que aplica la prueba de Lund (1975). Esta prueba nos dice si hay datos atípicos y cuáles son. install.packages("rapportools") # utilízalo si aún no tienes instalada la librería.

No hemos detectado datos atípicos (NULL=ninguno).
Normalidad: comprueba que la variable dependiente tiene distribución “aproximadamente" normal para cada categoría de la variable independiente.
Utilizaremos la prueba de normalidad de Shapiro-Wilks que funciona bien para conjuntos de datos pequeños. Para esta prueba la hipótesis nula implica que los datos siguen una distribución normal, y la hipótesis alternativa indica lo contrario. Por tanto, si el p-valor de la prueba es inferior a 0.05 (el nivel alfa de significación que se toma por defecto) rechazaremos la hipótesis nulas y diremos que la respuesta no sigue una distribución normal en cada grupo de estudio. En caso contrario, si el p-valor es mayor a 0.05, no estaremos incumpliendo el supuesto de normalidad.

En los 3 grupos la variable attractiveness tiene distribución normal pero debemos tener cuidado, ¡ya que solo tenemos 16 observaciones por grupo! también podríamos realizar gráficos q-q para evaluar este supuesto, que siempre es más preciso (¡lo dejo en vuestras manos!).
Homogeneidad de varianza: comprueba que las varianzas de la respuesta en cada grupo son iguales.
Utilizaremos distintos tipos de pruebas para evaluar la homocedasticidad (homogeneidad de varianza).Las diferencias entre las pruebas se deben a su sensibilidad al supuesto de normalidad visto anteriormente. Para esta prueba la hipótesis nula implica que los datos presentan homogeneidad de varianza entre los grupos, por lo cual si el p-valor es inferior a 0.05 estaríamos incumpliendo este supuesto. Si el p-valor es mayor a 0.05 existe homogeneidad de varianza.

En todos los casos obtenemos p>0.05, es decir, no encontramos problemas de heterocedasticidad (falta de homogeneidad de varianza).Las pruebas de normalidad y homogeneidad de varianza no indican problemas con los supuestos estadísticos clásicos, si bien debemos recordar que tenemos tan solo 16 sujetos por grupo.
¿Existen diferencias entre los grupos?: prueba ANOVA R
Recordemos nuestra pregunta. **Sin diferenciar por sexo, ¿al consumir alcohol los sujetos se vuelven menos selectivos a la hora de elegir pareja? ¿en qué momento se vuelven más selectivos? ¿con 2 pintas o con 4 pintas de alcohol?**Para el caso del ANOVA de un factor entre grupos, las hipótesis que corresponden son:
- H0: mu_None=mu_2pints=mu_4pints; el atractivo físico de las parejas de sujetos con distinto consumo de alcohol es similar (los sujetos, inependientemente del nivel de consumo de alcohol que tengan encima, son igual de selectivos a la hora de encontrar pareja).
- H1: alguno es distinto (existen diferencias entre al menos alguno de los 3 grupos de consumo de alcohol, alguno de ellos es más selectivo pero no indico cuál)
Prueba paramétrica: ANOVA de un factor entre-grupos.

Existen diferencias estadísticamente significativas entre los grupos de consumo de alcohol (F(2,45)=13.31, p<0.05).
¿Entre qué grupos hay diferencias?: pruebas post hoc
Como hemos detectado diferencias entre los grupos, nos preguntamos específicamente qué grupos son significativamente distintos. Para ello utilizamos la prueba de comparación múltiple post hoc de Tukey (también llamada prueba HSD).

Encontramos que existen diferencias entre 4 Pints-None y 4 Pints-2 Pints (p<0.001), pero no entre 2 Pints-None.Observando los gráficos y estadísticos descriptivos que hemos calculado anteriormente podemos afirmar que solo para 4 pintas de alcohol disminuye estadística y significativamente el nivel de atracción de las parejas.
Reflexión final sobre la prueba ANOVA R
No detectamos valores atípicos y los datos se distribuyeron de manera normal en cada grupo, como indicó la prueba de Lund para valores atípicos, el gráfico de cajas (Figura) y la prueba de normalidad de Shapiro-Wilks (p>.1), respectivamente.
Tampoco detectamos problemas de homogeneidad de varianza, como observamos en la prueba de Levene (p>.1).
El nivel de atracción de las parejas fue estadística y significativamente distinto entre los grupos de sujetos con diferente consumo de alcohol (F(2,45)=13.31, p<.05).El grupo de sujetos que no habían consumido alcohol (63.75±8.47) y el que consumió 2 pintas (64.69±9.91) presentaron valores similares en el atractivo de las parejas que encontraron, sin embargo, estos valores disminuyeron para el grupo que consumió 4 pintas (46.56±14.34). Solo se detectaron diferencias estadísticamente significativas al comparar con el último grupo. La prueba de comparaciones múltiple post hoc de Tukey indicó que la disminución en el atractivo de las parejas fue significativo desde 0 a 4 pintas (diferencia de medias-18.13, IC al 95% [-27.71, -8.54]) y desde 2 a 4 pintas (diferencia de medias=-17.19, IC al 95% [-26.78, -7.60]), pero no de 0 a 2 pintas (diferencia de medias=.94, IC al 95% [-8.65,10.52]). Dicho de otro modo, detectamos diferencias significativas en el atractivo de las parejas de sujetos con distinto consumo de alcohol, en particular vemos que los sujetos se volvieron menos selectivos en la búsqueda de pareja a partir de 4 pintas de alcohol. Moraleja, un poco de alcohol no nos hace menos selectivos en la búsqueda de pareja pero si nos pasamos... Como comentario final, recuerda que los datos también incluyen información sobre el sexo del sujeto analizado. Esto nos permitiría investigar si el efecto del consumo del alcohol sobre la selección de pareja ocurre antes en los hombres respecto a las mujeres, o viceversa. Analizar estos dos factores (consumo de alcohol y sexo) requiere una prueba ANOVA de dos vías, que veremos en un futuro post, ¿pero tú qué esperarías obtener? ¡Saludos!


