
Ellos y Ellas
Todos (o casi todos) conocemos ese famoso programa de televisión de citas exprés, donde la primera impresión cuenta. Sin embargo, ¿Quiénes son más selectivos a la hora de elegir pareja? ¿Ellos o ellas? Hoy vamos a responder a esta pregunta, ¿Tú qué crees que encontraremos?
La pregunta del millón
Vamos a utilizar un conjunto de datos muy simpático sobre la selección de pareja. Queremos comparar mujeres y hombres (sobrios) para evaluar si **existen diferencias en el atractivo de las parejas que escogen y qué sexo es más selectivo a la hora de encontrar pareja.**NOTA: Recuerda que utilizamos estos mismos datos, pero con otro enfoque, para evaluar el efecto del alcohol en la selección de pareja y determinar si nos volvemos menos selectivos cuando tomamos una copa de más, y en qué momento el alcohol hace su efecto (“the beer goggles effect»). Para verlo visita el post ¿Cómo realizar el ANOVA de una vía en R?
Comparación de la selección de pareja entre hombres y mujeres con R
Los datos goggles
Utilizaremos los datos “goggles” de la librería WRS2 de R, que recoge los efectos del alcohol en la selección de pareja en clubes nocturnos. Para acceder a los datos tienes que instalar y activar entonces el paquete WRS2 así:
> install.packages(“WRS2”) #instalar
> library(WRS2) #activarLuego ya estamos listos para abrir nuestros datos y observarlos:
> data("goggles”) #abre los datos
>?goggles #consultamos la descripción de los datos (se visualiza en la pestaña “Help” de la ventana inferior derecha de RStudio).Vemos entonces que se evaluaron 48 participantes (24 hombres y 24 mujeres) dividiéndolos en 3 grupos de 8 participantes cada uno. Los llevó a un club nocturno y a un grupo no le dio alcohol, otro tomó 2 pintas y el último 4 pintas de alcohol. Al final de la noche el investigador tomó una fotografía a la persona elegida por el participante y un grupo de jueces independientes evaluó el poder de atracción de dicha persona. Ahora veamos cómo está formada la base de datos:
> head(goggles) #nos muestra su encabezado de la base de datos (las 6 primeras líneas)
gender alcohol attractiveness
1 Female None 65
2 Female None 70
3 Female None 60
4 Female None 60
5 Female None 60
6 Female None 55
> dim(goggles) # vemos la dimensión de los datos (el número de filas y columnas)
[1] 48 3La base de datos tiene 3 variables:
• el sexo (variable gender, hombre o mujer),
• el alcohol consumido (variable alcohol, nada, 2 pintas o 4 pintas),
• el nivel de atracción física de la pareja encontrada (variable attractiveness, puntaje de 0 a 100 dado por los jueces)
NOTA: en estos datos el nivel de selectividad en la búsqueda de pareja se evalúa solamente valorando su atractivo físico.
La pregunta, ¿cuál era?
Vamos a plantearnos una pregunta inicial muy básica, para evaluar el punto de partida. Repito. Si comparamos mujeres y hombres (sobrios), ¿existen diferencias en el atractivo de las parejas que escogen? ¿qué sexo es más selectivo a la hora de encontrar pareja?Esto quiere decir que trabajaremos solo con los datos de los sujetos que no han bebido alcohol (alcohol=None), utilizaremos un subconjunto de los datos, y que vamos a comparar el atractivo de las parejas (attractiveness) entre los 2 sexos (gender, Female vs Male).
- Variable respuesta: atractivo de las parejas (attractiveness)
- Variable explicativa: sexo (gender, Female vs Male).
Como nuestra respuesta es numérica y estamos comparando 2 muestras independientes (mujeres vs hombres), vamos a utilizar la prueba paramétrica t de Student si se cumplen los supuestos clásicos de normalidad y homogeneidad de varianza, y si no encontramos problemas con valores atípicos (u outliers).Puedes consultar nuestra Guía definitiva para encontrar la prueba estadística que buscas para revisar por qué hemos elegido esta prueba de hipótesis**.**
NOTA: Por supuesto sería más interesante aún evaluar si luego de consumir alcohol las percepciones subjetivas del atractivo físico se vuelven menos rigurosas y si esto depende del sexo del sujeto (si ocurre con más frecuencia en los hombres respecto a las mujeres, o viceversa). Pero eso ya nos haría utilizar el ANOVA de 2 vías, lo dejamos para un próximo post si quieres.
¿Qué procedimiento debemos seguir?
De manera general, los pasos a seguir son:
- seleccionar la submuestra a analizar.
- realizar un análisis descriptivo de los datos.
- comprobar los supuestos (normalidad y homogeneidad de varianza) y presencia de outliers.
- seleccionar la prueba de hipótesis adecuada según la información previa
- realizar la prueba de hipótesis y decidir.
- interpretar los resultados.
Comenzamos por el principio: selección de la submuestra
Comenzaremos seleccionando la submuestra que vamos a utilizar, sujetos que no han consumido alcohol.
Vamos a crear un nuevo conjunto de datos llamado goggles2 donde solo se encuentren los sujetos sobrios (que no hayan tomado alcohol).
Utilizaremos la función subset() que viene instalada por defecto en R (¡yeah! Aquí no tenemos que instalar un nuevo paquete).
> #seleccionamos los sujetos sobrios
> goggles2<-subset(goggles, alcohol=="None”)
> goggles2 #observamos el objeto que hemos creado
gender alcohol attractiveness
1 Female None 65
2 Female None 70
3 Female None 60
4 Female None 60
5 Female None 60
6 Female None 55
7 Female None 60
8 Female None 55
25 Male None 50
26 Male None 55
27 Male None 80
28 Male None 65
29 Male None 70
30 Male None 75
31 Male None 75
32 Male None 65A continuación, realizamos los análisis descriptivos para tener una idea de cómo son nuestros datos y luego analizamos los supuestos de la estadística clásica para elegir cómo comparar los sexos (i.e. si debemos utilizar pruebas paramétricas, no paramétricas o robustas)
Observamos los patrones: estadística descriptiva
Antes de realizar la prueba de hipótesis siempre debemos realizar un análisis descriptivo de los datos. Primero comprobamos el número de casos que tenemos por grupo de análisis:
> table(goggles2$gender) #construimos una tabla de frecuencia para la variable gender
Female Male
8 8Comprobamos que tenemos 8 observaciones para hombres y 8 para mujeres. No son demasiadas, la verdad. Ahora calculamos varios estadísticos descriptivos para el atractivo de la pareja conseguida según el sexo del encuestado. Para ello utilizaremos la librería dplyr. Debes instalar y activar esta librería para realizar los cálculos, así:
> install.packages(“dplyr”) #instalar
> library(dplyr) # activar
> # calcular varios estadísticos por grupo
> summarise(group_by(goggles2, gender),
+ media = mean(attractiveness),
+ mediana = median(attractiveness),
+ varianza = var(attractiveness),
+ desvest = sd(attractiveness),
+ CV = (sd(attractiveness) / mean(attractiveness) * 100))
# A tibble: 2 x 6
gender media mediana varianza desvest CV
<fct> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Female 60.6 60 24.6 4.96 8.17
2 Male 66.9 67.5 107. 10.3 15.4
Tenemos que el atractivo medio de las parejas de los hombres encuestados es mayor que el de las mujeres encuestadas, al igual que la mediana (que es una medida de centralidad menos sensible a la presencia de outliers), pero que la variabilidad del atractivo físico de la pareja es mayor también en los hombres.
Y como un gráfico vale más que mil palabras, o que mil datos (Errores Comunes que Puedes Evitar con un Simple Gráfico), vamos a graficarlo.
El mejor paquete de R para realizar gráficos de alta calidad es ggplot2, así que instálalo y actívalo para crear un gráfico fabuloso.
Si aún no conoces el paquete ggplot2 te invito a visitar nuestro post ¿Cómo realizar gráficos elegantes con R? Usa ggplot2
> install.packages(“ggplot2”) #instalar
> library(ggplot2) # activar
> # realizamos el gráfico
> ggplot(goggles2, aes(x = gender, y = attractiveness)) +
+ geom_boxplot() +
+ labs(title = "Atractivo de las parejas en función a sexo del encuestado",
+ x = "Sexo",
+ y = "Atractivo físico”)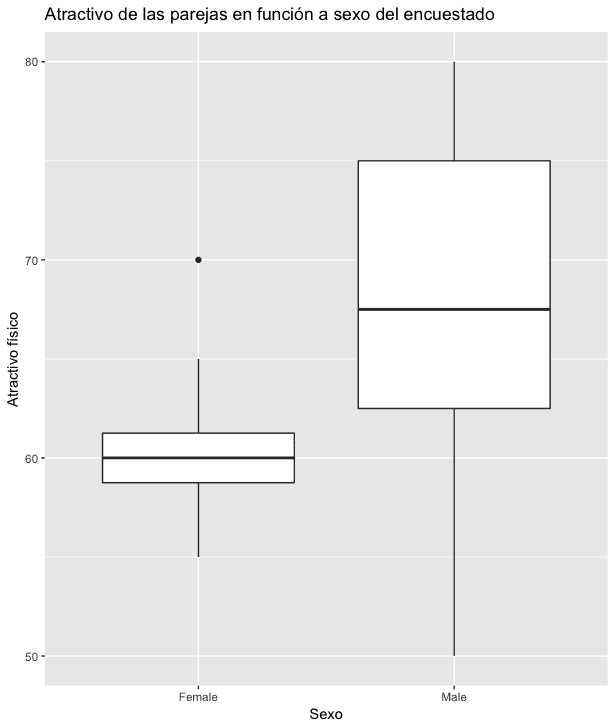
Aquí puedes observar lo que hemos comentado en los estadísticos descriptivos.
El punto se que observa en el gráfico representa a un dato atípico u outlier.
NOTA: recordemos que tan solo tenemos 8 observaciones por grupo.
¿Podrías decidir si el nivel de atractivo físico de las parejas conseguidas es igual (o no) entre hombres y mujeres?
La estadística descriptiva nos puede ayudar a identificar relaciones y patrones, pero no nos permite obtener conclusiones más allá de los datos que tenemos (responden a la muestra con la que trabajamos, no a la población de la cuál proceden).
La estadística inferencial sí nos permite realizar conclusiones sobre la población de estudio más allá de los datos -muestra- que tengamos. Así que vamos a realizar una prueba de hipótesis para contestar a nuestra pregunta.
Comprobación de los supuestos clásicos: normalidad y homogeneidad de varianza
Este paso nos ayudará a seleccionar la prueba de hipótesis adecuada para nuestros datos. Como mencionamos al principio, en el caso de que se cumplan los supuestos de normalidad y homogeneidad de varianza, optaremos por las pruebas paramétricas, en el caso de incumplimiento podremos optar por pruebas no paramétricas o por pruebas robustas.
NOTA: también existen otras opciones, como utilizar transformaciones de las variables o aumentar la muestra en caso de que podamos.
Lee la Guía definitiva para encontrar la prueba estadística que buscas En este caso tenemos muy pocos datos, por lo cual no es de esperar que no se cumplan estos supuestos, podríamos incluso no evaluarlos y pasar directamente a pruebas no paramétricas.
Pero para mostrar el procedimiento habitual vamos a realizar las pruebas pertinentes para evaluar los supuestos de normalidad y homogeneidad de varianza.
Prueba de hipótesis para evaluar la normalidad de los datos
Cuando tenemos muestras pequeñas es recomendable utilizar la prueba de normalidad de Shapiro-Wilks. Debemos evaluarla por grupo, eso lo indicamos en la función by(), así:
> #prueba de normalidad por sexo
> by(goggles2$attractiveness, goggles2$gender, shapiro.test)
goggles2$gender: Female
Shapiro-Wilk normality test
data: dd[x, ]
W = 0.87152, p-value = 0.156
----------------------------------------------------------------
goggles2$gender: Male
Shapiro-Wilk normality test
data: dd[x, ]
W = 0.94106, p-value = 0.6215Vemos que en ninguno de los casos rechazamos la hipótesis nula de normalidad, pero recuerda… son 8 datos por grupo.
Prueba de hipótesis para evaluar la homogeneidad de varianza de los datos
Podemos utilizar la prueba de igualdad de varianza de Levene, la de Bartlett (ambas sensible a desviaciones de la normalidad, aunque Levene es un poco mejor en esos casos), o la de Fligner (menos sensible a la falta de normalidad, ya que es una prueba no paramétricadica).
Elige una de estas pruebas según tus datos y realiza el contraste. Aquí veremos las 3 para que tengas un ejemplo de cada una.
Prueba de Bartlett.
> bartlett.test(goggles2$attractiveness, goggles2$gender)
Bartlett test of homogeneity of variances
data: goggles2$attractiveness and goggles2$gender
Bartlett's K-squared = 3.2475, df = 1, p-value = 0.07153La prueba de Levene se encuentra en el paquete car, así que tienes que instalarlo y activarlo previamente.
> install.packages("car")
> library(car)
> leveneTest(goggles2$attractiveness, goggles2$gender)
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 1 4.3922 0.05476 .
14
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Y por último la prueba de Fligner:
> fligner.test(goggles2$attractiveness, goggles2$gender)
Fligner-Killeen test of homogeneity of variances
data: goggles2$attractiveness and goggles2$gender
Fligner-Killeen:med chi-squared = 3.7295, df = 1, p-value = 0.05346En los 3 casos no rechazamos la hipótesis nula de igualdad de varianzas, aunque el p-valor es cercano al 0.05 y debemos recordar nuevamente que solo tenemos 8 observaciones por grupo.Si no tuviéramos el problema de pocos datos ni el del outlier que hemos identificado, siguiendo los resultados que hemos obtenido para los sueustos, diríamos que los datos cumplen con los supuestos clásicos y que por tanto podemos utilizar una prueba paramétrica para contrastar nuestra hipótesis de igualdad de atractivo físico de las parejas de hombres y mujeres.
NOTA: si deseas discutir cuál es el mejor procedimiento para los casos donde tenemos una muestra de pequeño tamaño, déjanos tu comentario en este post.
Ponemos a prueba nuestra afirmación: estadística inferencial
Si comparamos mujeres y hombres sobrios, ¿existen diferencias en el atractivo de las parejas que escogen? ¿qué sexo es más selectivo a la hora de encontrar pareja?Es decir, **cuando están sobrios ¿los hombres y las mujeres son igualmente selectivos para seleccionar su pareja?.**En este caso como son 2 muestras independientes y se cumplen los supuestos hemos dicho que utilizaríamos la **prueba t de Student.**Para hacerlo sencillo vamos a aplicar pruebas bilaterales.
En este caso las hipótesis a contrastar son:
Prueba bilateral
Aquí queremos evaluar si existen o no diferencias entre sexos a la hora se seleccionar la pareja por su atractivo físico cuando los sujetos están sobrios.
Sea mu la media poblacional, tenemos las siguientes hipótesis que queremos contrastar:
-
H0: muF=muM. Para sujetos sobrios, el atractivo físico de las parejas de hombres (M) y mujeres (F) es similar (sobrios ambos sexos son igual de selectivos a la hora de encontrar pareja).
-
H1 : muF ≠ muM. Lo contrario (sobrios existen diferencias entre sexos en la selección de pareja, alguno de ellos es más selectivo pero no indico cuál)
NOTA: Si se quiere realizar comparaciones unilaterales basta con agregar el argumento alternative=“less” o alternative=“greater”.Utilizaremos la función t.test() que viene instalada por defecto en R para realizar el contraste de hipótesis paramétrico.
Recuerda que el programa selecciona el orden de las categorías a comparar según su orden alfabético, en este caso primero Female y luego Male, esto te ayudará a escribir las hipótesis. Los datos los ingresamos en formato de fórmula “Y~X”:
> t.test(attractiveness~gender, goggles2)
Welch Two Sample t-test
data: attractiveness by gender
t = -1.543, df = 10.06, p-value = 0.1537
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-15.267737 2.767737
sample estimates:
mean in group Female mean in group Male
60.625 66.875NOTA: por defecto la función utiliza el argumento var.equal=F.
Interpretación final y cómo comunicar tus resultados
La prueba de hipótesis nos indica que no existen diferencias significativas entre sexos en el nivel de atracción física de sus parejas cuando se encuentran sobrios (t(10.06)=-1.543, p = 0.1537).
Esto se debe a que, en promedio el nivel de atracción de las parejas de los hombres es mayor que el de las mujeres (66.88 frente a 60.62), pero como su variabilidad -sd- también es mayor (10.33 frente a 4.96), las diferencias no son significativas (ver el gráfico de cajas realizado).
¿Te ha gustado este tutorial? Si es así, déjanos tu comentario y si no te ha gustado también, queremos escuchar tu opinión ;).
¡Saludos!


