
¿Qué es la correlación y qué es la causalidad?
La correlación implica que dos variables se mueven juntas: cuando una cambia, la otra tiende a hacerlo también. Sin embargo, esto no significa que una variable sea la causa de la otra. Es simplemente una medida estadística de asociación.
Por el contrario, la causalidad implica que una variable provoca directamente un cambio en otra. La relación causal es direccional y se basa en un mecanismo subyacente que genera ese efecto.
Diferencias clave entre correlación y causalidad
- La correlación no implica causalidad: dos variables pueden estar asociadas sin que una cause a la otra.
- La causalidad implica una relación de causa y efecto, pero no necesariamente una correlación observable.
- La correlación es simétrica, la causalidad no: si A causa B, no significa que B cause A.
Ejemplos que demuestran que la correlación no es causalidad
Correlación sin causalidad
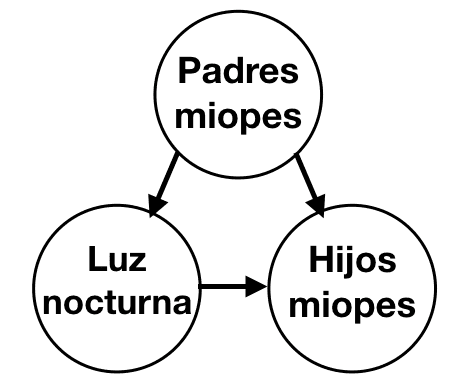
Por ejemplo, un estudio de 1999 publicado en Nature mostró que los niños menores de dos años que dormían con luces nocturnas tenían más probabilidades de tener miopía. Más tarde, otros investigadores demostraron que los padres miopes tenían más probabilidades de mantener sus luces encendidas por la noche. Puede ser que los padres fueran una causa común del uso de luces nocturnas y, en virtud de la herencia genética, la miopía se transmitió a sus hijos.
Causalidad sin correlación
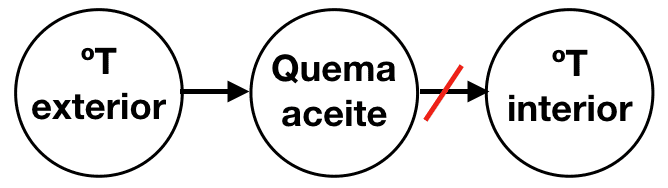
Supongamos que un termostato mantiene un hogar a una temperatura constante controlando un horno de aceite. Dependiendo de la temperatura exterior, se quemará más o menos aceite. Pero como el termostato mantiene la temperatura interior constante, la temperatura interior no tendrá correlación con la cantidad de aceite quemado. El aceite es lo que mantiene la casa caliente, una relación causal, pero no está correlacionada con la temperatura de la casa.
Dirección de la causalidad
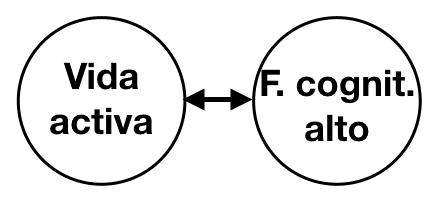
Por ejemplo, se ha afirmado que los estilos de vida activos pueden proteger el funcionamiento cognitivo de las personas mayores. Pero algunas evidencias sugieren que la dirección causal es la opuesta: un funcionamiento cognitivo más alto puede resultar en un estilo de vida más activo.
También podemos encontrarnos con otro tipo de problemas.
Correlaciones espurias por tercera variable
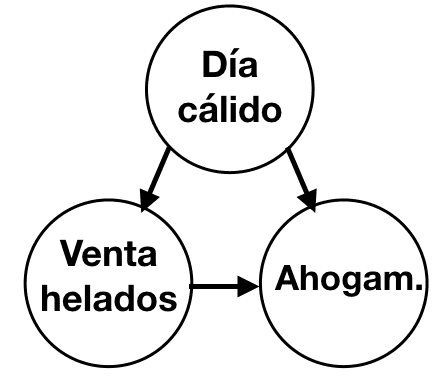
Por ejemplo, Hyndman & Athanasopoulos 2018 han visto que existe una relación entre el número mensual de ahogamientos en una playa con la cantidad de helados vendidos en el mismo período. Los helados no causan el ahogamiento, ni a la inversa, sino que las personas comen más helados en los días calurosos cuando también es más probable que vayan a nadar. Entonces, las dos variables (ventas de helados y ahogamientos) están correlacionadas, pero una no está causando la otra sino que ambas son causados por una tercera variable, la temperatura.
La relación entre la venta de helados y el número de ahogamientos es espuria.
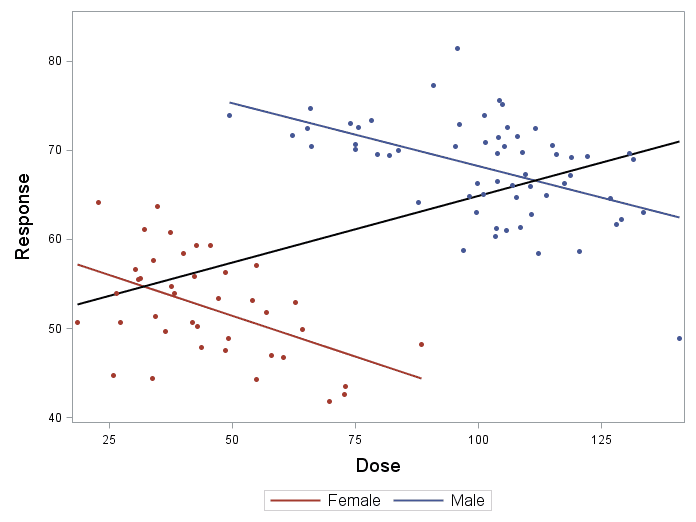
La paradoja de Simpson
Esta paradoja ocurre cuando una tendencia aparente en los datos globales se revierte o desaparece al analizar los subgrupos por separado.
Imagina un estudio sobre la eficacia de un medicamento. A nivel general, los resultados parecen indicar que a mayor dosis, mayor eficacia. Sin embargo, al separar por sexo se observa que la relación cambia: las mujeres (que recibieron dosis más bajas) respondieron menos al tratamiento que los hombres, lo que distorsiona la tendencia global.
Cómo detectar relaciones espurias o falsas
Correlación parcial
Permite evaluar la relación entre dos variables mientras se controla el efecto de una tercera. Por ejemplo, si se observa una correlación entre ventas de helados y ahogamientos, la correlación parcial al controlar por la temperatura nos dirá si esa relación persiste o era espuria.
Estratificación y control de variables
Dividir el análisis en grupos según una variable de interés (como sexo, edad, región) permite aislar efectos y evitar falsas asociaciones debidas a variables de confusión.
Conclusión: ¿cómo evitar malas interpretaciones?
- No confundas correlación con causalidad.
- Usa técnicas como la correlación parcial o el análisis estratificado para detectar variables de confusión.
- Apóyate en experimentos controlados cuando sea posible para establecer relaciones causales.
La correlación puede ser una pista valiosa, pero solo el análisis crítico y el contexto permiten descubrir si hay una relación causal real.


