
¿Cuántas veces hemos querido revisar un análisis estadístico meses o años después de haberlo realizado y no hemos sido capaces, bien porque no recordamos cómo hacerlo o los datos no están fácilmente disponibles?
¿Cuánto tiempo perdemos en rehacer análisis estadísticos, figuras o tablas tras corregir un error en los datos, o siguiendo las recomendaciones de un revisor?
¿Cuánto tiempo invertimos intentando implementar un nuevo método de análisis a partir de la escueta descripción proporcionada en un artículo?
¿Cuántas veces hemos intentado recabar datos infructuosamente porque los autores han perdido los datos, su formato es ilegible hoy en día, o simplemente se niegan a compartirlos?
Así comienza el artículo de Rodríguez-Sánchez et al. (2016) sobre «Ciencia reproducible» y es que, como mencionan, todas estas escenas son desgraciadamente frecuentes en el día a día de los científicos, y evidencian un grave problema de reproducibilidad en ciencia (Peng 2011).
La inmensa mayoría de los artículos científicos no son reproducibles, esto es, resulta muy difícil o imposible trazar claramente el proceso de obtención de los resultados y volver a obtenerlos (reproducirlos) ¡incluso tratándose del mismo equipo de autores! (Rodríguez-Sánchez et al. 2016)
En este artículo te traemos un interesante ejemplo real para discutir este problema, te presentamos las ventajas de adoptar flujos de trabajo reproducibles, e introducimos las principales herramientas para ello.
¡Espero que lo disfrutes!
- Los errores de Reinhart & Rogoff.
- ¿Qué es una investigación reproducible?
- ¿Cómo hacemos para que nuestras investigaciones sean reproducibles?
- ¿Cuáles son los beneficios de practicar una ciencia reproducible?
- Referencias
Los errores de Reinhart & Rogoff.
En 2010 Carmen M. Reinhart y Kenneth S. Rogoff publicaron el paper “Growth in a time of debt” el cual fue increíblemente influyente a la hora de decidir las políticas económicas a tomar durante la crisis. Pero hubo un importante problema con este trabajo. En el 2013 un grupo de investigadores compuesto por Thomas Herdon, Michael Ash y Robert Pollin repitieron los análisis y encontraron que el estudio contenía algunos importantes errores.
- Errores de código. Debido a un error cometido con la hoja de cálculo excluyeron a cinco países con una importante deuda y alto crecimiento, estos son Australia, Austria, Bélgica, Canadá y Dinamarca.
- Errores de manipulación de los datos. Excluyeron del cómputo algunos países y algunos años en los que de nuevo había una deuda remarcable y alto crecimiento, como son Australia, Nueva Zelanda y Canadá entre los años 46 y 50.
- Errores de cálculo estadístico. Ponderaron los datos de forma que algunas observaciones de muchos años con altas deudas se resumen en una observación.
Tras solucionar estos problemas, los investigadores encontraron que el crecimiento medio real del PIB para los países que tienen un ratio de deuda-pública/PIB superior al 90% era del 2.2% y no del -0.1% como habían publicado Reinhart y Rogoff. Por lo tanto el crecimiento a este ratio del 90% no era demasiado diferente al de los ratios deuda-pública/PIB menores. Se desmoronaba una de las principales conclusiones del estudio.¿Moraleja? estos errores se hubieran podido detectar rápidamente si los investigadores Reinhart y Rogoff hubieran hecho el informe reproducible.
La trazabilidad y reproducibilidad de los resultados son condiciones inherentes a la ciencia de calidad.
¿Qué es una investigación reproducible?
Dicho de manera sencilla, un estudio científico es reproducible si se dispone del código capaz de recrear todos los resultados a partir de los datos originales (Peng 2011).
El código no es más que un texto interpretable por un ordenador que permite repetir, a partir de los datos originales, todos los análisis estadísticos (manipulación de datos, figuras, tablas, pruebas estadísticas) incluidos en un trabajo. Es decir, nos permite observarpaso a paso cómo se ha realizado el trabajo.
Podemos definir un gradiente de reproducibilidad (¡vaya palabreja!, Figura 1).
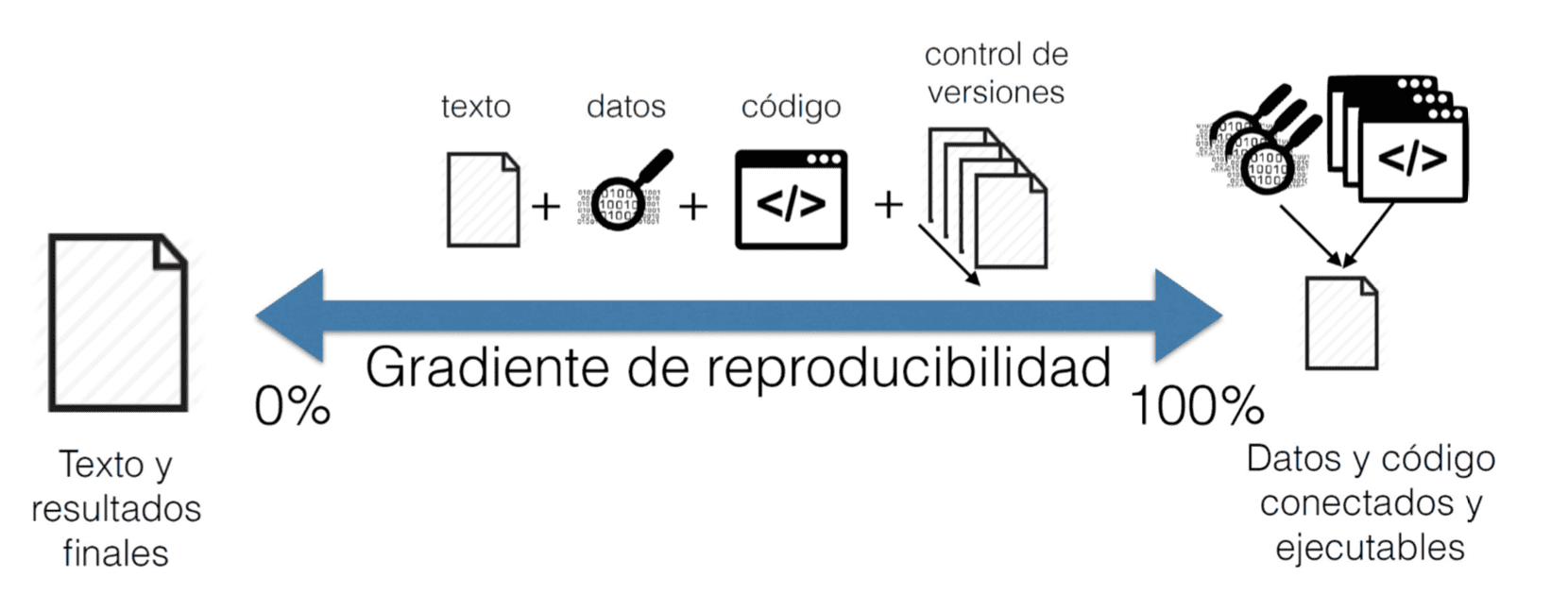
Figura 1. La reproducibilidad no es una cualidad binaria sino un gradiente (Peng 2011). Los artículos científicos que sólo contienen el texto, resultados y figuras finales (por ejemplo en un único archivo pdf) son los menos reproducibles: es imposible reconstruir detalladamente el proceso de análisis desde los datos originales hasta los resultados finales. La publicación de los datos y/o el código empleado para el análisis contribuyen a mejorar la reproducibilidad. Igualmente, la existencia de un sistema de control de versiones (como git) permite reconstruir perfectamente la historia del proyecto. Finalmente, en el extremo del gradiente de reproducibilidad se encuentran los documentos dinámicos (por ejemplo, Rmarkdown) que integran perfectamente texto, datos y código ejecutable. In Rodríguez-Sánchez et al. 2016
¿Cómo hacemos para que nuestras investigaciones sean reproducibles?
R, RMarkdown y Github.
Una de las principales enseñanzas del ejemplo que hemos visto es que debemos utilizar formatos que permitan detectar los errores que podemos cometer durante un análisis. Esto incluye evitar el uso de archivos binarios (como los de Excel) que no permiten hacer control de versiones de manera que se revele el proceso de investigación. Es decir, debemos ser capaces de registrar cómo se ha ido creando el análisis, superando y corrigiendo los problemas que surgen durante este.
Aquí es donde entra en juego el software gratuito R. R ha mejorado fundamentalmente nuestro enfoque de la investigación colaborativa, haciendo que todo nuestro flujo de trabajo sea más transparente y racionalizado. Al hacer nuestro trabajo mediante la ejecución de código, es más difícil cometer errores producidos por el arrastre de celdas y clics de ratón inadecuados como en Excel o SPSS. Al tener los datos originales en un archivo separado también es más difícil destruir o cambiar estos por error. Además, nos permite disponer de los datos en un formato que los hace más sencillos de distribuir, por ejemplo un .csv más el script en R.
Debido a que R usa formatos abiertos, nos permite hacer control de versiones y usar, por ejemplo, una plataforma como GitHub.com para compartir nuestro trabajo. Así podremos mostrar cómo ha sido creado del documento y análisis de nuestro trabajo, y dejar constancia de los cambios hechos paso a paso. Al tener un acceso más sencillo a nuestros datos (en un .csv por ejemplo) y código del análisis, otras personas pueden replicarlo paso a paso, encontrar errores y proponernos una solución a través de la plataforma, en la cual, a su vez quedaría todo este trabajo registrado.
Otra cuestión muy interesante es que R al integrar también herramientas para la creación de informes como R Markdown nos permiten evitar muchos errores relacionados con el copiar y pegar a un editor de texto. Es muy complicado que unos resultados sean mal copiados ya que R Markdown se encarga de insertarlos por nosotros. Además podemos compartir nuestro archivo .Rmd y nuestros datos originales para que otras personas puedan controlar cómo ha sido creado nuestro informe. Aunque decidamos no mostrar código en el informe final en pdf o doc, en el .Rmd quedará todo registrado.
Debajo puedes ver representado el proceso de un trabajo reproducible que te hemos contado (Figura 2).
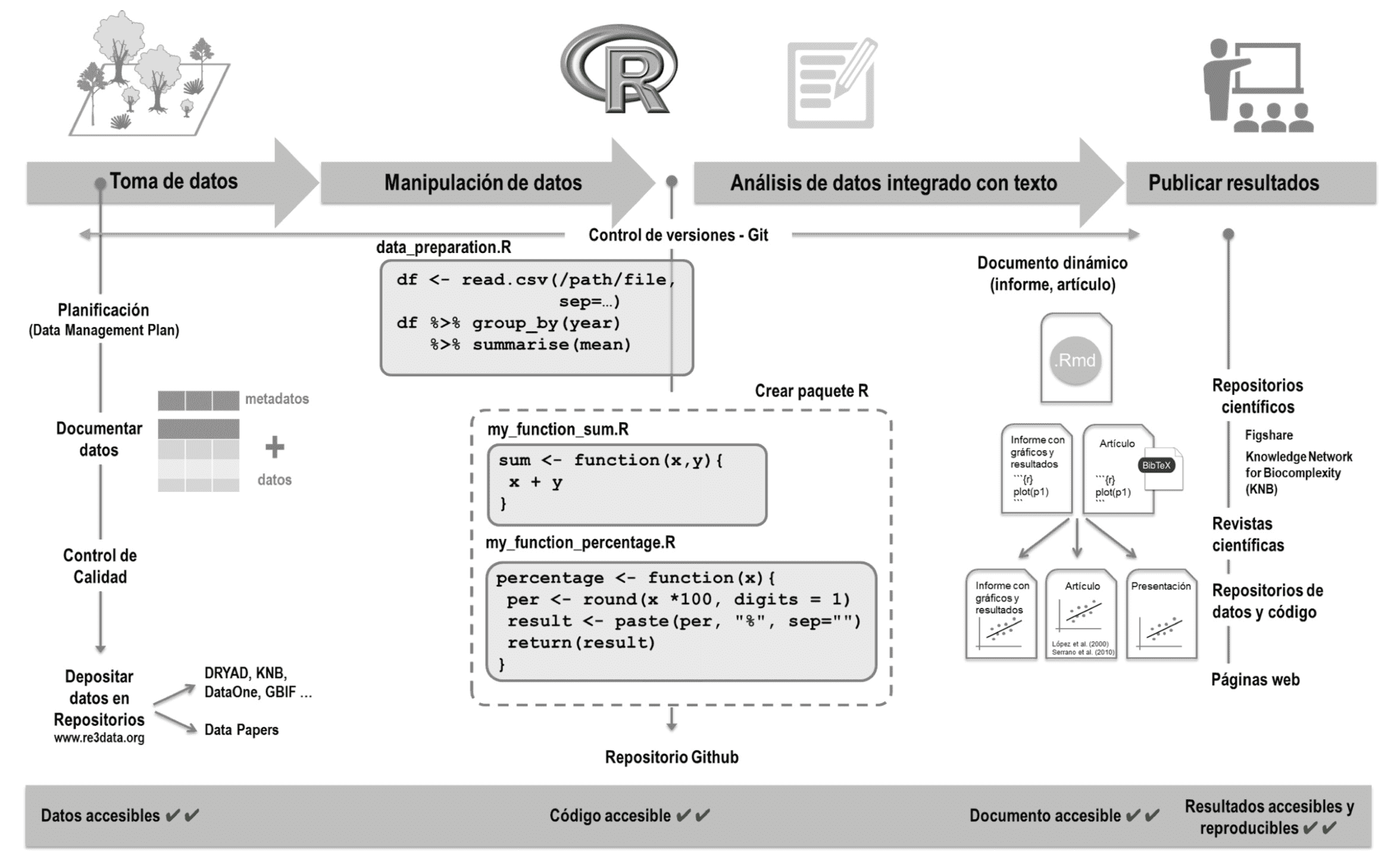
Figura 2. Esquema de un flujo de trabajo reproducible. En primer lugar, los datos se recogen según un protocolo bien diseñado, se documentan con metadatos, se someten a un control de calidad (mediante funciones de código), y se almacenan en un repositorio de datos en la nube. Después procederíamos al análisis, siempre guardando la información en códigos. El análisis propiamente dicho se puede realizar mediante documentos de Rmarkdown que integran texto, código y resultados (tablas y figuras). Estos documentos pueden convertirse fácilmente en presentaciones, páginas web, o artículos científicos plenamente reproducibles. In Rodríguez-Sánchez et al. 2016
Y aquí tienes un resumen de las principales herramientas científicas de datos abiertos que se pueden utilizar para mejorar la reproducibilidad, la colaboración y la comunicación, por tarea (Figura 3).
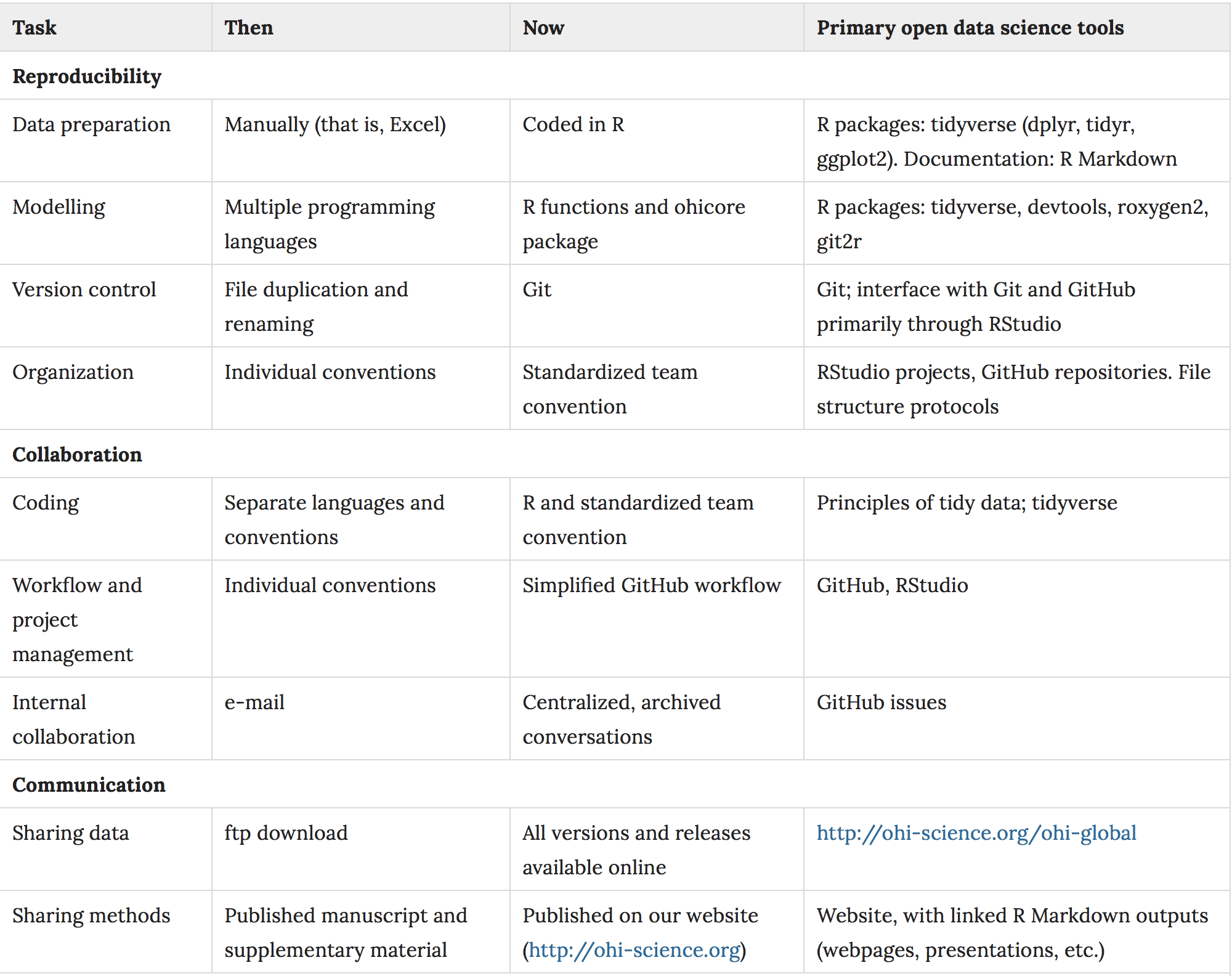
Figura 3. La transición al uso de herramientas de datos abiertos (R, RStudio, RMarkdown, GitHub) por tarea. In Munafò et al. (2017).
¿Cuáles son los beneficios de practicar una ciencia reproducible?
“Every analysis you do on a dataset will have to be redone 10-15 times before publication. Plan accordingly.” Trevor A. Branch.
Es cierto, es difícil detallar todo el proceso de análisis y obtención de resultados a partir de un conjunto de datos, pero la ciencia reproducible no sólo acelera el progreso científico sino que también reporta múltiples beneficios para el investigador (Munafò et al. 2017). Por ejemplo, un trabajo reproducible puede ahorrarnos tiempo y esfuerzo, y aumentar la calidad (se reduce drásticamente el riesgo de errores) e impacto de nuestros trabajos (Rodríguez-Sánchez et al. 2016).
¿Y ahora?, anímate a dar el salto a R/RMarkdown y cuéntanos tu experiencia.
Referencias
- Herndon, T., Ash, M., & Pollin, R. (2014). Does high public debt consistently stifle economic growth? A critique of Reinhart and Rogoff. Cambridge journal of economics, 38(2), 257-279. Enlace.
- Lowndes, J. S. S., et al. (2017). Our path to better science in less time using open data science tools. Nature ecology & evolution, 1(6), 0160. Enlace.
- Munafò, M. R., et al. (2017). A manifesto for reproducible science. Nature Human Behaviour, 1, 0021.
- Peng, R.D. 2011. Reproducible Research in Computational Science. Sci- ence 334: 1226-1227. Enlace
- Reinhart, C. M., & Rogoff, K. S. (2010). Growth in a Time of Debt. American Economic Review, 100(2), 573-78. Enlace.
- Rodriguez-Sanchez, F., Pérez-Luque, A. J., Bartomeus, I., & Varela, S. (2016). Ciencia reproducible: qué, por qué, cómo. Revista Ecosistemas, 25(2), 83-92. Enlace.


