
Los árboles de decisión son una herramienta fundamental en Machine Learning y análisis de datos. Su éxito no radica en ser el modelo más preciso, sino en su facilidad de interpretación y en su versatilidad. Esta guía te enseñará qué son, cómo funcionan, cómo se construyen y cuándo es conveniente utilizarlos.
¿Qué son los árboles de decisión?
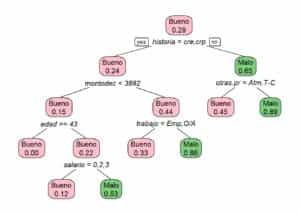
Un árbol de decisión es un modelo predictivo que organiza decisiones y sus posibles consecuencias en forma de un diagrama similar a un árbol. A través de preguntas binarias o categóricas, divide los datos en subconjuntos homogéneos, facilitando tanto la clasificación como la regresión.
Dependiendo del tipo de variable objetivo:
Variable numérica ➜ problema de regresiónVariable categórica ➜ problema de clasificación
Origen e historia de los árboles de decisión
La metodología moderna de árboles de decisión se popularizó en 1984 con la publicación del libro Classification and Regression Trees (CART), creado por Leo Breiman, Jerome Friedman, Richard Olshen y Charles Stone. Desde entonces, se ha convertido en una de las técnicas más intuitivas y utilizadas en ciencia de datos.

¿Qué tipo de algoritmo es un árbol de decisión?
Los árboles de decisión son algoritmos supervisados, es decir, necesitan datos etiquetados para aprender. Son muy usados tanto para tareas de clasificación como de regresión, dependiendo de la naturaleza de la variable dependiente.
Estructura básica de un árbol de decisión
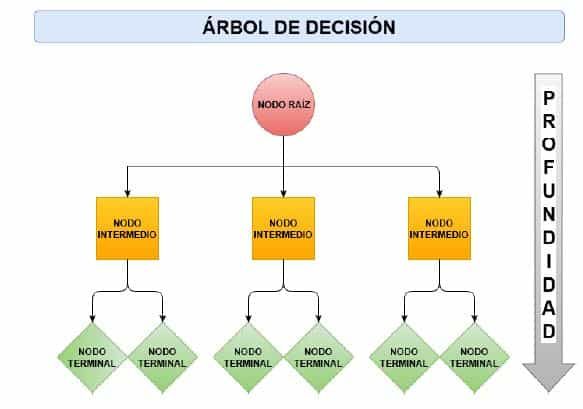
Un árbol se lee de arriba hacia abajo y está compuesto por:
- Nodo raíz: punto inicial donde se hace la primera división.
- Nodos internos: decisiones intermedias que subdividen los datos.
- Hojas (nodos terminales): resultados o predicciones finales.
Además, se habla de profundidad del árbol como el número máximo de divisiones desde la raíz a una hoja.
¿Cómo se construye un árbol de decisión?
La construcción de un árbol se basa en dividir los datos en subconjuntos puros (con elementos de la misma clase o valor). Para ello, se utilizan diferentes criterios de partición, según el tipo de problema:
Para clasificación:
- Índice Gini: mide la impureza. Menor Gini, mejor división.
- Entropía + Ganancia de Información: mide el desorden y selecciona la división que más lo reduce.
Para regresión:
- RSS (Residual Sum of Squares): mide el error entre los valores reales y predichos. Se busca minimizarlo.
El algoritmo más conocido para construir estos árboles es el algoritmo de Hunt.
Ventajas y desventajas de los árboles de decisión
✅ Ventajas
- Fáciles de construir e interpretar.
- No requieren suposiciones estadísticas complejas.
- Pueden manejar datos con valores faltantes.
- Trabajan con variables numéricas y categóricas sin necesidad de codificarlas.
- Permiten relaciones no lineales entre variables.
- Seleccionan automáticamente las variables más relevantes.
❌ Desventajas
- Alta tendencia al sobreajuste (overfitting).
- Sensibles a valores atípicos.
- Pueden ser inestables: pequeños cambios en los datos generan estructuras muy distintas.
- Los árboles grandes pueden volverse difíciles de interpretar.
- En regresión, no suelen ser tan precisos como otros modelos.
- Si las clases están desbalanceadas, pueden generar árboles sesgados.
Cómo crear un árbol de decisión
La creación de un árbol de decisión de un problema de clasificación se lleva a cabo aplicando el algoritmo de Hunt que se basa en la división en sub-conjuntos que buscan una separación óptima. Dado un conjunto de registros de entrenamiento de un nodo, si pertenecen a la misma clase se considera un nodo terminal, pero si pertenecen a varias clases, se dividen los datos en sub-conjuntos más pequeños en función de una variable y se repite el proceso.
Para seleccionar qué variable elegir para obtener la mejor división se puede considerar el Error de Clasificación, el índice Gini (rpart) o la Entropía (C50).
El índice de Gini mide el grado de pureza de un nodo. Nos mide la probabilidad de no sacar dos registros de la misma clase del nodo. A mayor índice de Gini menor pureza, por lo que seleccionaremos la variable con menor Gini ponderado. Suele seleccionar divisiones desbalanceadas, donde normalmente aísla en un nodo una clase mayoritaria y el resto de clases los clasifica en otros nodos.
Se define el índice de Gini como:
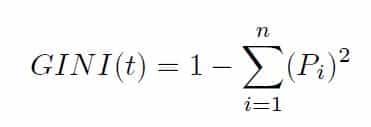
Donde Pi es la probabilidad de que un ejemplo sea de la clase i.
La entropía es una medida que se aplica para cuantificar el desorden de un sistema. Si un nodo es puro su entropía es 0 y solo tiene observaciones de una clase, pero si la entropía es igual a 1, existe la misma frecuencia para cada una de las clases de observaciones.
La entropía tiende a crear nodos balanceados en el número de observaciones. Relacionado con la entropía se define la Ganancia de Información que busca la división con mayor ganancia de información, es decir, con menor entropía ponderada de la variable.
Se define la entropía como:
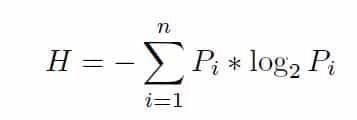
Donde Pi es la probabilidad de que un ejemplo sea de la clase i.
En el caso de los árboles de decisión de un problema de regresión se utiliza el RSS (Residual Sum of Squares) que es una medida de la discrepancia entre los datos reales y los predichos por el modelo. Un RSS bajo indica un buen ajuste del modelo a los datos, es decir, se busca minimizar el RSS.
Se define el RSS como:
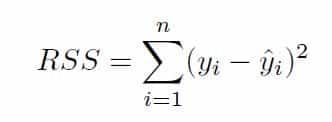
Donde yi es el valor real de la variable a predecir y ˆyi es el valor predicho.


