
¿Qué es el tamaño muestral y por qué importa?
El tamaño muestral es la cantidad de individuos, observaciones o unidades de análisis que se incluyen en un estudio. Es un componente fundamental en la planificación de una investigación cuantitativa, ya que determina la precisión y validez de los resultados. Un tamaño muestral adecuado asegura que los resultados obtenidos sean representativos de la población y reduce la posibilidad de errores tipo I (falsos positivos) y tipo II (falsos negativos).
Además, un tamaño insuficiente puede llevar a conclusiones erróneas, mientras que un tamaño excesivo puede generar costos innecesarios o sobrepotenciar el estudio, detectando efectos estadísticamente significativos que no son relevantes en la práctica.
Factores que influyen en el cálculo del tamaño muestral
El cálculo del tamaño muestral depende de varios factores interrelacionados:
- Nivel de significancia (α\alphaα): Probabilidad de cometer un error tipo I. Comúnmente se fija en 0.05.
- Potencia deseada (1−β1 - \beta1−β): Generalmente se busca una potencia del 80% o 90%.
- Tamaño del efecto esperado: Magnitud del efecto que se espera encontrar. Puede basarse en estudios previos, criterio clínico o un estudio piloto.
- Variabilidad o desviación estándar: Relevante para variables continuas, afecta la precisión de las estimaciones.
- Tipo de análisis o prueba estadística: Dependiendo de si es una t de Student, ANOVA, regresión, chi cuadrado, etc., el tamaño muestral requerido puede variar.
- Diseño del estudio: Estudios con grupos independientes, mediciones repetidas o diseños más complejos requieren ajustes específicos.
¿Cómo se calcula el tamaño muestral?
El cálculo puede hacerse utilizando fórmulas estadísticas específicas o herramientas de software como G*Power, Stata, R o incluso calculadoras en línea. Para realizarlo, es necesario definir previamente:
- El nivel de significancia (α\alphaα)
- La potencia deseada (1−β1 - \beta1−β)
- El tamaño del efecto
- La desviación estándar (si aplica)
- El tipo de prueba que se aplicará
Por ejemplo, en G*Power se selecciona el tipo de prueba (e.g., prueba t para dos medias independientes), se ingresan los valores de α\alphaα, 1−β1 - \beta1−β, y el tamaño del efecto, y el programa devuelve el tamaño muestral requerido por grupo. Además, es común ajustar el resultado para compensar posibles pérdidas de participantes durante la recolección de datos.
¿Qué es la potencia estadística?
La potencia estadística es la probabilidad de detectar un efecto real cuando este realmente existe (es decir, rechazar correctamente la hipótesis nula cuando es falsa). Se calcula como 1−β1 - \beta1−β, donde β\betaβ es la probabilidad de cometer un error tipo II.
Esta se relaciona directamente con el tamaño muestral: a mayor tamaño muestral, mayor potencia estadística, y viceversa. Si un estudio tiene baja potencia, corre el riesgo de no detectar efectos verdaderos, incluso si estos existen. Por eso, al diseñar un estudio, se busca una potencia comúnmente de 80% o 90%, lo cual implica que hay un 80-90% de probabilidad de detectar un efecto si realmente existe.
¿Para qué necesitamos conocer la potencia?
¿Realmente no hay efecto o es que el estudio no fue capaz de detectarlo? ¿los resultados son realmente tan positivos o es que el experimento sobreestima los efectos del tratamiento? si tu análisis tiene una baja potencia estadística los resultados suelen ser difíciles de interpretar.
Debemos plantear nuestros experimentos de tal manera de obtener un gran poder de contraste, y así estar seguros de que seremos capaces de evidenciar el efecto estudiado.
¿Cuál sería un valor aceptable de potencia?
Generalmente un valor de potencia de 0.80 es aceptable y se puede usar como punto de referencia. Los investigadores suelen diseñar sus experimentos de tal manera de que sus resultados sean significativos el 80% de las veces.
¿Cómo mejorar la potencia?
Los ruidos de tratamiento (problemas experimentales o de instrumento) y de fondo (respuestas con alta variabilidad) no se pueden controlar, pero sí podemos diseñar adecuadamente nuestro experimento de tal manera que obtengamos una potencia alta.
La potencia de una prueba estadística está relacionada con:
- El tamaño de la muestra «n»: el número de casos o sujetos que participan del estudio.
- El nivel de significación «alfa»: la probabilidad de rechazar la hipótesis nula cuando ésta es verdadera (error tipo I o falso positivo). Se suele asumir un 5% o, lo que es lo mismo, un nivel de confianza del 95% (1-alfa).
- El tamaño del efecto «d» o «r»: es una medida del cambio en una respuesta. Simplificando un poco podemos calcular medidas que reflejen las diferencias de medias entre grupos (la diferencia de medias dividido la desviación estándar) o medidas que indiquen la relación entre variables (coeficiente de correlación), según nuestro objetivo.
Una baja potencia podría indicar un tamaño de muestra pequeño, un alfa menor o un tamaño del efecto pequeño, y lo contrario para una potencia alta.
Ejemplos prácticos de cálculo del tamaño muestral
Ejemplo 1: Cálculo a priori con dos grupos (t-test)
El siguiente ejemplo es una adaptación del libro «R in Action» de Robert Kabacoff (2011).
Imagine que medimos el tiempo de reacción de las personas ante unos cambios que se producen en un simulador. Tenemos dos grupos de sujetos, uno en los cuales los sujetos están a la vez hablando por teléfono y otros que no.
- A priori. Queremos comparar el tiempo medio de reaccion de los participantes en ambos grupos. Conocemos de la bibliografía que el tiempo de reacción tiene una desviación estándar (SD) de 1.25 segundos y que una diferencia en 1 segundo en el tiempo de reacción se considera una diferencia importante (el tamaño del efecto sería d=1/1.25=0.8 -la diferencia de medias dividido la SD-). Para una potencia del 90% y un nivel de confianza del 95%, ¿cuántos participantes necesitamos en nuestro estudio?
Si realizamos los cálculos, por ejemplo, con el paquete «pwr» de R, obtenemos:
library(pwr)
pwr.t.test(d=.8, sig.level=.05, power=.9, type="two.sample",alternative="two.sided")
34 sujetos en cada grupo (en total 68 sujetos) para detectar un tamaño de efecto de 0.8, con una potencia del 90% y un nivel de confianza del 95%.
Ejemplo 2: SITUACIONES NUEVAS
- Queremos comparar 5 grupos, con 25 sujetos por grupo, para un nivel de significación del 5%.
Calculamos la potencia de la prueba para distintos valores de tamaño de efecto (f):
pwr.anova.test(k=5,n=25,f=0.10,sig.level=.05) #power = 0.1180955
pwr.anova.test(k=5,n=25,f=0.25,sig.level=.05) #power = 0.5738
pwr.anova.test(k=5,n=25,f=0.40,sig.level=.05) #power = 0.9569163La potencia será de 11.8% para detectar un efecto pequeño, 57.4% para detectar un efecto moderado y 95.7% para detectar un efecto grande.
Dada la limitación de los tamaños muestrales, solo podremos tratar de encontrar un efecto grande.
- Veamos ahora la sensibilidad de nuestros parámetros.
Calculemos los tamaños muestrales necesarios para detectar el rango del tamaño del efecto.
library(pwr)
es <- seq(.1, .5, .01)
nes <- length(es)
samsize <- NULL
for (i in 1:nes){
result <- pwr.anova.test(k=5, f=es[i], sig.level=.05, power=.9)
samsize[i] <- ceiling(result$n)
}
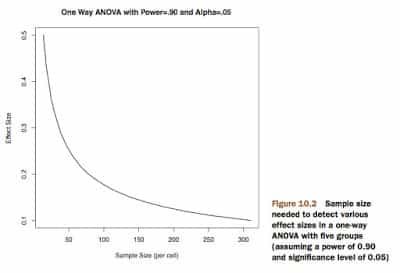
plot(samsize,es, type="l", lwd=2, col="red",ylab="Effect Size",xlab="Sample Size (per cell)", main="One Way ANOVA with Power=.90 and Alpha=.05")
Este gráfico nos permite estimar el impacto de cambiar las condiciones de nuestro diseño experimental.
Podemos ver que en este caso, para 5 grupos experimentales, invertir dinero en aumentar el tamaño muestral encima de 200 observaciones por grupo no es útil.
La Potencia Estadística nos permite estimar los efectos de cambiar las condiciones de nuestro diseño experimental.
Ejemplo 3: Representación del tamaño muestral
- Vamos a utilizar un ejemplo para graficar el tamaño muestral que necesitaríamos utilizar en una investigación según los valores del tamaño del efecto (en este caso medido mediante el coeficiente de correlación) y la potencia estadística asumida.
Es decir, queremos determinar el tamaño muestral necesario para decidir si el coeficiente de correlación es estadísticamente significativo, según un rango de valores de tamaño de efecto y poder estadístico:
library(pwr)
# Set range of correlations & power values
r <- seq(.1,.5,.01)
nr <- length(r)
p <- seq(.4,.9,.1)
np <- length(p)
# Obtain sample sizes
samsize <- array(numeric(nr*np), dim=c(nr,np))
for (i in 1:np){
for (j in 1:nr){
result <- pwr.r.test(n = NULL, r = r[j],sig.level = .05, power = p[i], alternative = "two.sided")
samsize[j,i] <- ceiling(result$n)
}
}
# Set up graph
xrange <- range(r)
yrange <- round(range(samsize))
colors <- rainbow(length(p))
plot(xrange, yrange, type="n",xlab="Correlation Coefficient (r)",ylab="Sample Size (n)" )
# Add power curves
for (i in 1:np){
lines(r, samsize[,i], type="l", lwd=2, col=colors[i])
}
# Add annotations
abline(v=0, h=seq(0,yrange[2],50), lty=2, col="grey89")
abline(h=0, v=seq(xrange[1],xrange[2],.02), lty=2,col="gray89")
title("Sample Size Estimation for Correlation Studies\n
Sig=0.05 (Two-tailed)")
legend("topright", title="Power", as.character(P), fill=colors)Observamos que necesitamos un tamaño muestral de aproximadamente 75 para detectar una correlación de 0.20 con un 40% de confianza.
También necesitamos 185 observaciones más (n=260) para detectar la misma correlación con 90% de confianza.
Este gráfico puede utilizarse también para otro tipo de pruebas estadísticas, solo basta con modificar algunos pasos.
La Potencia Estadística nos permite decidir el tamaño de muestras que necesitamos para nuestro experimento.
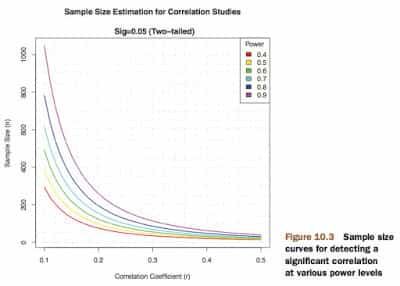
ste último gráfico es original de https://www.statmethods.net/stats/power.html
¿Te ha parecido útil el post? ¿conocías la importancia de la potencia estadística? ¿cómo calculas el tamaño muestral de tu investigación? ¡deja tu comentario!
Referencias de interés
* Cohen, Jacob (1988). «Statistical power analysis for the behavioral sciences» (2nd ed.). Hillsdale, NJ: Lawrence Earlbaum Associates.


