Analizando la correlación con la librería Caret
Caret nos facilita el realizar muchos de los procesos de un Data Science para la resolución de problemas de clasificación y regresión con el lenguaje R, de una forma sencilla y fácil.
En la entrada de hoy analizaremos la correlación de un conjunto de datos, pero antes de empezar nos podemos preguntar...
¿Qué es la correlación entre variables?
La correlación es un tipo de relación entre dos variables numéricas, que evalúa la tendencia en los datos. Cuando tenemos dos variables con alta correlación podemos eliminar una de ellas al tener el mismo efecto sobre la característica a predecir o dependiente. Mantener estas variables puede hacer que obtengamos un peor rendimiento de nuestro modelo.
¿Cómo utilizar caret para el análisis de correlación? Un ejemplo con los datos Sonar
Cuando nos enfrentamos a un conjunto de datos, ¿quién no se ha enfrentado a la decisión de tener que eliminar variables altamente correlacionadas? Caret nos facilita un método para tomar la decisión.
Realizamos un ejemplo práctico donde utilizaremos el conjunto de datos de la librería mlbench denominado Sonar (Gorman, RP y Sejnowski, TJ.1988) que está compuesto por 61 variables y 208 observaciones. El problema que queremos resolver consiste en identificar entre las señales de un sonar que rebotan en un cilindro de metal y las que rebotan en una roca aproximadamente cilíndrica, siendo la variable dependiente Class.
Veamos cómo realizar con caret el análisis de correlación en 5 pasos sencillos.
Paso 1
Lo primero que hacemos es cargar las librerías y datos que utilizaremos:
- El paquete Caret para eliminar las características altamente correlacionadas.
- El paquete mlbench donde se encuentra el dataset.
- El paquete dplyr para el manipulado de los datos.
#Cargamos las librerías
library(caret)
library(mlbench)
library(dplyr)
#Cargamos los datos
data("Sonar")
Paso 2
El siguiente paso es crear una matriz de correlaciones, por lo que tenemos que eliminar aquellas características que no sean numéricas. En nuestro caso es un paso sencillo, porque en el conjunto de datos solo hay una variable factor que es Class.
#Nos quedamos con las variables numéricas
sonar_num <- Sonar %>% select(- Class)
Paso 3
Una vez que hemos seleccionado las características numéricas, obtenemos la matriz de correlaciones con la función cor(). Recordar que dicha función nos calculará la correlación entre las distintas variables numéricas utilizando el método Pearson por defecto, pero que podemos indicarle otros métodos (“pearson”, “kendall”, “spearman”).
# Matriz de correlaciones
sonar_cor <- cor(sonar_num)
Paso 4
La matriz de correlaciones que hemos calculado la debemos indicar en la función findCorrelation() donde además podemos añadir los siguientes parámetros:
- cutoff: límite de correlación absoluta por pares. Este parámetro nos sirve para señalar el umbral para 1 que la función considere que dos variables están altamente correlacionadas. En este caso hemos elegido un punto de corte de 0.90 que es bastante exigente.
- Verbose: para indicarle que nos detalle o no el proceso.
- names: si indicamos TRUE nos devolverá el nombre de las variables a eliminar. Si indicamos FALSE nos mostrará los índices, donde se encuentran las variables.
La función buscará las variables que tienen una correlación alta entre si (en nuestro caso superior a 0.90) y, una vez las tenga identificadas, calculará la correlación absoluta media de cada variable con el resto de variables del conjunto de datos, eliminando aquellas con la correlación absoluta media más grande.
findCorrelation(sonar_cor, cutoff = 0.90, verbose = T, names = T)
## Compare row 15 and column 16 with corr 0.913
## Means: 0.281 vs 0.229 so flagging column 15
## Compare row 18 and column 17 with corr 0.926
## Means: 0.256 vs 0.227 so flagging column 18
## Compare row 20 and column 21 with corr 0.905
## Means: 0.244 vs 0.227 so flagging column 20
## All correlations <= 0.9
## [1] "V15" "V18" "V20"
La función nos indica que hay tres variables que debemos eliminar de nuestro conjunto de datos como son la “V15”, “V18” y “V20”. Estudiamos cada caso:
- La variable 15 con la 16 tiene una correlación de Pearson de 0.913, pero la media de las correlaciones de la característica 15 con el resto es de 0.281 y de la 16 de 0.229. Al ser mayor la media de la variable 15 al de la 16, se elimina la primera.
- La segunda relación con correlación superior a 0.90 es entre la variable 18 y la 17 con 0.926. En este caso la media de las correlaciones entre el resto de variables es superior en la 18 que se selecciona para eliminar.
- Por último, la función nos identifica como alta la correlación entre la variable 20 y 21 con 0.905, eliminando la 20 al tener una media superior con las demás variables.
Paso 5
Por último, debemos realizar gráficos de dispersión para visualizar la relación entre las variables, así nos aseguramos de que las relaciones son lineales o al menos monótonas y de que no existen valores anómalos (outliers) que puedan distorsionar los valores de correlación.
Por ejemplo, para representar la relación entre las 3 primeras variables del conjunto de datos según la clase (Class), escribimos:
featurePlot( x = Sonar[,1:3], y = Sonar[,61], plot = "ellipse", auto.key = list(columns = 2))))
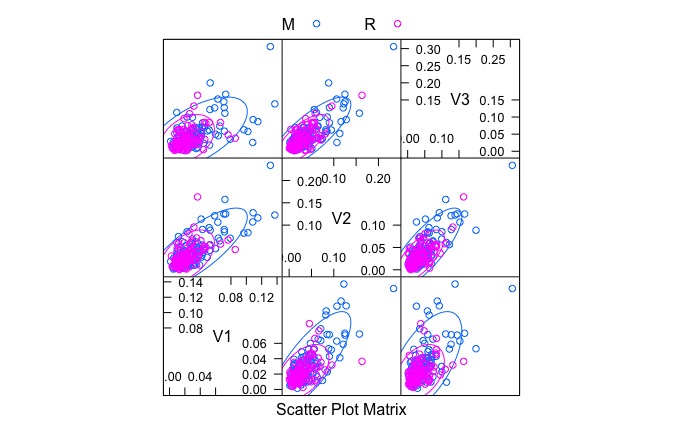
En el gráfico observamos una relación positiva, bastante monótona pero dispersa, sobretodo para la clase M.
Si quieres conocer más sobre este gran paquete (caret)
no te pierdas nuestro curso de especialización.
Curso de Machine Learning con Caret en R

Conclusión
De una forma sencilla el paquete Caret con R nos ha identificado las variables con mayor correlación a partir del umbral marcado, para después facilitarnos un método para eliminar una de ellas entre los pares altamente correlacionados.
Este es un pequeño ejemplo de cómo utilizar la librería para resolver problemas de regresión y clasificación con Caret y R, pero puedes encontrar mucha más información en la documentación oficial o en nuestro curso de Machine Learning con Caret, una librería fundamental para ser un auténtico Data Science.
Artículo de Nacho García
 Ciencia de datos
Ciencia de datosMáster en Estadística Aplicada para Data Science con R Software
CONVOCATORIA ABIERTA | INICIO ABRIL 2024 > Logra la máxima precisión y rigor en tus proyectos de Ciencia de Datos.
Precio ConsultarDuración 10 meses – 66 ECTS
 Ciencia de datos
Ciencia de datosMáster en Machine Learning con R
CONVOCATORIA ABIERTA | INICIO ABRIL 2024 > Automatiza procesos y crea tus propios algoritmos de Machine Learning.
Precio CONSULTARDuración 10 meses – 66 ECTS
0 comentarios
Nadie ha publicado ningún comentario aún. ¡Se tu la primera persona!