¿Qué es la correlación?
A menudo estamos interesados en observar y medir la relación entre 2 variables numéricas. Por ejemplo, si queremos evaluar la relación entre:
- las inversiones realizadas en explotaciones agrícolas y el rendimiento obtenido en cientos de miles de euros,
- las horas que se dedican a estudiar una asignatura y la calificación obtenida en el examen correspondiente,
- la relación entre una medida de agresividad y la edad de los sujetos evaluados,
- si estamos en una fábrica de piezas mecánicas y queremos analizar la relación entre la porosidad y la resistencia de las piezas.
En este post veremos cómo visualizar las relaciones a través deldiagrama de dispersión. Utilizaremos un ejemplo clásico de la literatura, como es el cuarteto de Anscombe, para comprender por qué este gráfico debe ser el primer paso a realizar en un análisis de correlación.
Luego veremos cómo medir la relación entre 2 variables mediante el coeficiente de correlación. Para ello vamos a ver qué tipo de coeficiente seleccionar según el tipo de datos que tenemos.
Visualización con diagramas de dispersión
Para ello, vamos a graficar una nube de puntos colocando una variable en el eje “x” (horizontal) y otra en el eje “y” (vertical).
No vamos a distinguir cuál variable va en cada eje porque no necesitamos diferenciar entre variable respuesta y variable explicativa.
Lo que nos interesa es identificar el tipo de relación o asociación entre ambas variables, su dispersión y si existen datos que se comportan de manera atípica (también llamados outliers).
¿Qué observar en un scatterplot?
El diagrama de dispersión nos permite observar características importantes de la relación.
Forma: lineal o no lineal
Si observas la siguiente figura tienes un ejemplo de relación Lineal a la izquierda y un ejemplo de relación no lineal (pero monótona) a la derecha.

Al determinar la forma de la relación, seremos capaces de seleccionar el estadístico adecuado para medir la relación, que veremos luego.
Outliers
La Presencia o no de datos atípicos (Outliers), puntos que no se ajustan al comportamiento del resto de la nube.
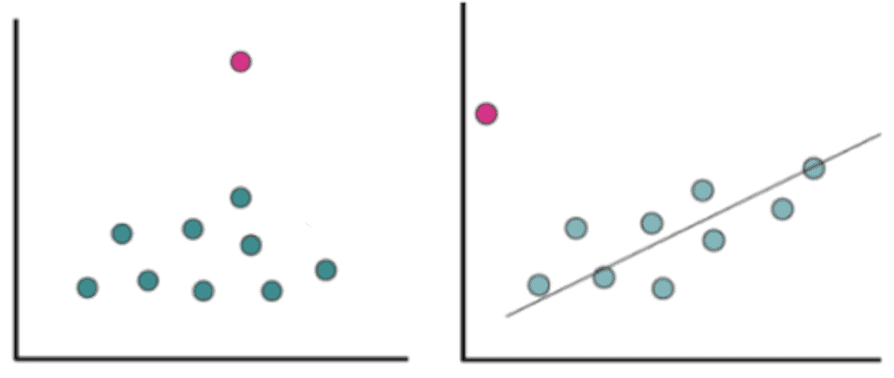
Los outliers pueden afectar los análisis de correlación y/o regresión debido a que la relación entre las dos variables cambia con la presencia de estos valores. Más adelante veremos qué estadístico de correlación elegir para disminuir su influencia sobre la medida de asociación que queremos calcular.
Dirección: positiva o negativa
Si existe una tendencia de aumento diremos que la relación es Positiva o directa, si por el contrario la tendencia es de disminución diremos que es una relación negativa o inversa.
También podríamos observar que no existe ningún tipo de asociación entre ellas si no observamos ningún patrón, es decir, si la nube de puntos se dispersa al azar.
Fuerza de la relación
La Fuerza de la relación, que representa qué tanta dispersión existe en los puntos.
Si existe poca dispersión a lo largo de la tendencia diremos que la relación es fuerte, mientras que si la dispersión es grande o la nube de puntos es circular, diremos que la relación es débil.
En el siguiente gráfico tenemos varios ejemplos del patrón que podemos obtener en un diagrama de dispersión. ¿Te animas a describir la dirección y fuerza de la relación en cada caso?
- Dirección: Positiva o negativa.
- Fuerza: Qué tanta dispersión existe.

Ejemplo de aplicación en R: diagrama de dispersión con ggplot2
En R utilizamos la función ggplot() del paquete ggplot2 para crear gráficos de dispersión de gran calidad. Debemos especificar el conjunto de datos donde se encuentran las variables (en el argumento data), qué variable irá en cada eje (con el argumento estético aes, identificando el eje “x” y el eje “y”) y por último indicamos que queremos ver la nube de puntos de los datos con geom_point().
En este ejemplo utilizamos el conjunto de datos stackloss del paquete MASS que corresponde a datos de una fábrica de oxidación de compuestos, que registra una medida de la producción de la fábrica (el flujo del aire; Air Flow) y otra medida de la ineficiencia de la planta (la pérdida de ácido a través de la pila; stack.loss). Queremos observar cómo se relacionan ambas medidas.

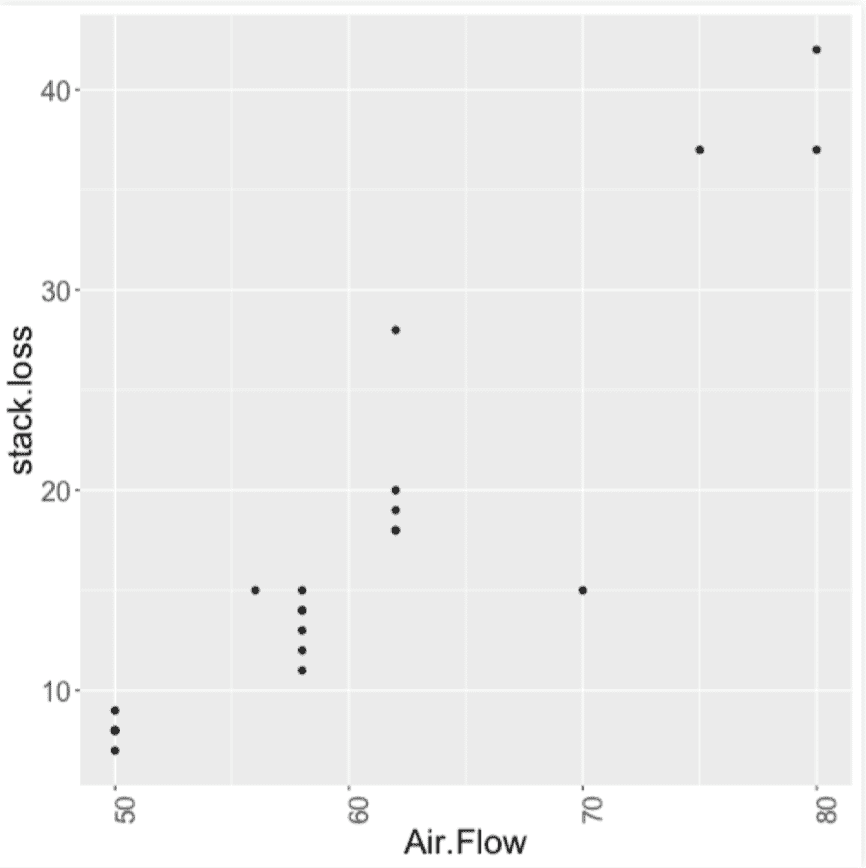
En nuestro gráfico observamos una relación lineal, positiva, bastante fuerte o con poca dispersión, y donde no parecen haber grandes problemas de presencia de datos atípicos.
Ejemplo de aplicación en R: el cuarteto de Anscombe
Veamos otro ejemplo para entender la importancia de graficar las variables antes de analizar su correlación o crear un modelo de regresión.
Tenemos 4 conjuntos de datos con variables "x" e "y" que tienen las mismas propiedades estadísticas tradicionales (igual media, varianza, correlación, línea de regresión, etc.), pero donde las relaciones son bastante diferentes.
- Conjuntos de datos muy diferentes puedentener valores de correlación similares.
- Para no cometer errores de interpretación, debemos tener en cuenta la curvatura y la presencia de datos atípicos.
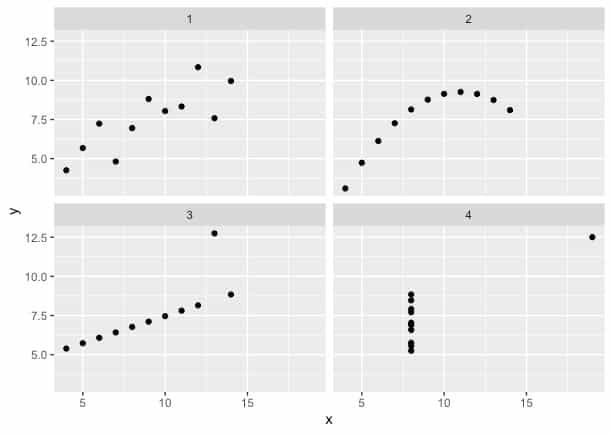
- En el primer gráfico observamos una relación lineal, sin outliers, positiva y bastante fuerte.
- En el segundo la relación no es lineal.
- El tercer conjunto de datos muestra una relación lineal, positiva y muy fuerte, pero presenta un outlier que puede disminuir su valor de correlación porque escapa al comportamiento general.
- Y en el último vemos que no existe realmente una relación entre “x” e “y”, sino que existe un outlier que puede confundir los resultados.
Cómo medir la correlación entre variables
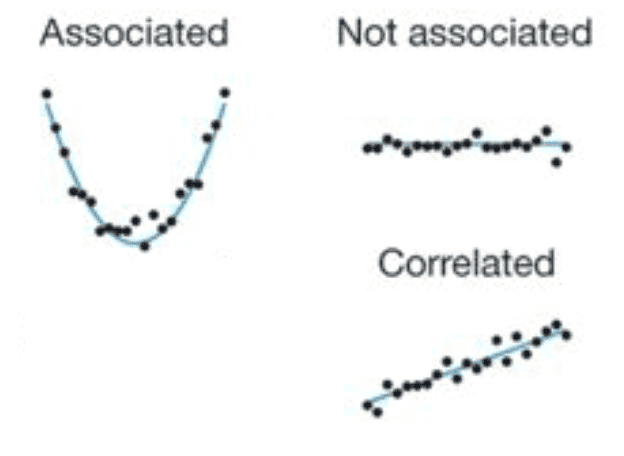
Dos variables están asociadas cuando una variable nos da información acerca de la otra.
Por el contrario, cuando no existe asociación, el aumento o disminución de una variable no nos dice nada sobre el comportamiento de la otra variable.
- La correlación es un tipo de asociación entre dos variables, específicamente evalúa una tendencia (creciente o decreciente) en los datos.
- Dos variables se correlacionan cuando muestran una tendenciacreciente o decreciente.
¿Qué mide un coeficiente de ocrrelación?
La correlación nos indicael signo y magnitud de la tendencia entre dos variables.
Signo
El signo nos indica la dirección de la relación, como hemos visto en el diagrama de dispersión.
- un valor positivo indica una relación directa o positiva,
- un valor negativo indica relación inversa o negativa,
- un valor nulo indica que no existe una tendencia entre ambas variables (puede ocurrir que no exista relación o que la relación sea más compleja que una tendencia, por ejemplo, una relación en forma de U).
Magnitud
La magnitud nos indica la fuerza de la relación, que toma valores entre -1 a 1.
Interpretación del valor
Cuanto más cercano sea el valor a los extremos del intervalo (1 o -1) más fuerte es la tendencia de las variables, o menor es la dispersión existe en los puntos alrededor de dicha tendencia. Cuanto más cercano sea a 0 sea el coeficiente de correlación, más débil será la tendencia, es decir, más dispersión habrá en la nube de puntos.
- si la correlación vale 1 o -1 diremos que la correlación perfecta,
- si la correlación vale 0 diremos que las variables no están correlacionadas.
En el gráfico vemos diferentes valores del coeficiente de correlación y sus diagramas de dispersión correspondientes.

Tamaño del efecto según Cohen
Para interpretar qué tan fuerte es la correlación podemos utilizar el criterio de Cohen de 1988, quién para valores absolutos indica que valores entre:
- 1-.3 representan un efecto pequeño,
- 3-.5 un efecto medio y
- >= .5 un efecto grande.
Son valores arbitrarios que te pueden servir de guía, pero te recomiendo interpretar la fuerza (o tamaño) de la correlación según el contexto de tu investigación. No es lo mismo analizar datos de un experimento físico controlado donde habrá menor dispersión, que analizar datos sociales o biológicos donde se espera encontrar menores valores de correlación debido a la gran cantidad de dispersión o variabilidad de los datos.
Tipos de coeficientes de correlación
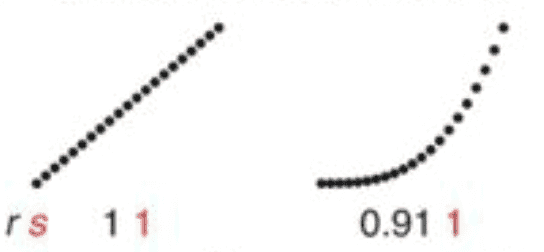
Tenemos el coeficiente de correlación lineal de Pearson que se sirve para cuantificar tendencias lineales, y el coeficiente de correlación de Spearman que se utiliza para tendencias de aumento o disminución, no necesariamente lineales pero sí monótonas (las variables tienden a moverse en la misma dirección relativa, pero no necesariamente a un ritmo constante).
Vemos representado con una “r” negra el coeficiente de Pearson y con una “s” en rojo el de Spearman, para una relación lineal y una relación monótona.
- Correlación de Pearson (r): tendencias lineales.
- Correlación de Spearman (s): tendencias monótonas.
Coeficiente de correlación lineal de Pearson
Entonces, el coeficiente de correlación lineal de Pearson mide una tendencia lineal entre dos variables numéricas.
Es el método de correlación más utilizado pero asume que:
- la tendencia debe ser de tipo lineal.
- no existen valores atípicos (outliers).
- las variables deben ser numéricas. Si las variables son de tipo ordinal (como las preguntas en escala de likert), no podremos aplicar la correlación de Pearson.
- tenemos suficientes datos(algunos autores recomiendan tener más de 30 puntos u observaciones).
Los dos primeros supuestos se pueden evaluar simplemente con un diagrama de dispersión, mientras que para los últimos basta con mirar los datos y el diseño que tenemos.
Ejemplo de aplicación en R: función cor()
Para calcular el coeficiente de correlación utilizaremos la función cor() que viene instalada por defecto en los paquetes básicos de R.
Podemos ingresar las variables como vectores. No importa cuál es “x” y cuál es “y”, porque la relación es simétrica.
Aquí seguimos con el ejemplo de los datos de la fábrica de oxidación de compuestos y calculamos la correlación entre las variables Air.Flow y stack.loss.

Vemos que la correlación lineal entre ellas es positiva y alta r=.92.
Coeficiente de correlación de Spearman
Si bien hemos visto que la relación entre Air.Flow y stack.loss era una tendencia lineal. Veamos ahora, por motivos didácticos, cómo calcularíamos el coeficiente de correlación de Spearman para el caso de que la tendencia fuera monótona en aumento o disminución.
Este coeficiente primero calcula el orden de los datos, sus rangos, y luego a estos valores le calcula el coeficiente de correlación lineal de Pearson.
Utilizamos la misma función cor() que antes pero ahora especificamos que el método sea el de Spearman.

Obtenemos un valor de correlación positivo y alta, no varía mucho de la anterior, vale r=.92, esto se debe a sí se cumplen las condiciones de la correlación de Pearson.
Este coeficiente es útil para los casos en los que trabajamos con datos ordinales (como las escalas de likert de los cuestionarios) o cuando no tenemos demasiados datos, o cuando la relación no es lineal pero sí monótona.
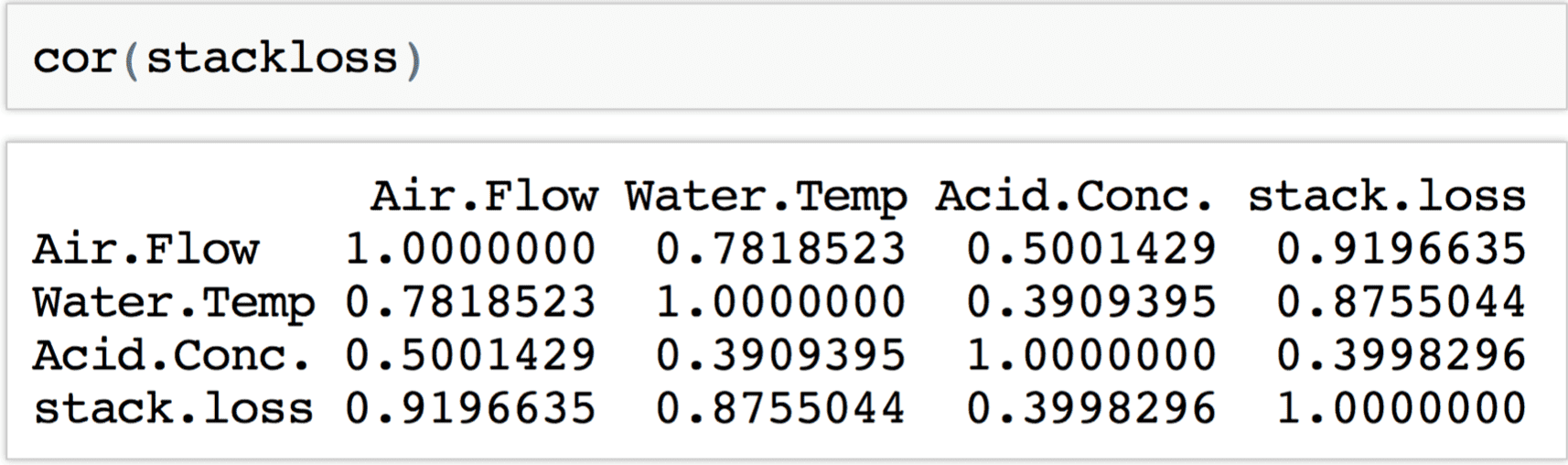
Correlación para una matriz de variables
La función cor() que hemos visto también permite ingresar múltiples variables como una única Matriz o data frame.
Aquí cada columna ha de representar una variable distinta.
Esta opción es útil si, por ejemplo, queremos calcular en un solo paso todas las correlaciones entre las variables del conjunto de datos stackloss.
Cómo tratar los datos perdidos o ausentes (NAs)
Por último, hay que tener en cuenta que cuando nuestro conjunto de datos tiene algún valor ausente o perdido (indicado por NA de Not Available), la función cor() nos devuelve otro NA.
Para especificar cómo queremos que se traten los valores ausentes en la función cor() utilizamos el argumento use:
- Si indicamos use = "pairwise.complete.obs": calcula el coeficiente de correlación para aquellas observaciones en las que no faltan ningún valor de “x” ni “y”.

¡No te olvides! El análisis de correlación es un paso clave en la construcción de modelos más complejos.
Ahora te toca a ti, ponlo en práctica con tus datos y cuéntame lo que observas.
Saludos.


