
El «arte» de la construcción de modelos
Generalmente los investigadores tenemos un conjunto de variables predictoras (o explicativas) candidatas y queremos identificar el modelo óptimo, seleccionar aquellas variables predicadoras que son más apropiadas para incluir en nuestro modelo.
El problema está cuando el número de variables predictoras candidatas es grande, porque entonces el número de posibles modelos de regresión también será grande.
En estos casos necesitamos especial alguna ayuda para seleccionar el modelo más adecuado para nuestros datos.
Existen algunas técnicas automáticas de selección de modelos pero en este artículo te invito a que tomes las riendas de tus análisis y consideres algunos aspectos claves que puedes pasar por alto si solo utilizas criterios de automatización.

Un modelo es una simplificación de la realidad destinada a promover la comprensión de los problemas que queremos abordar.
Por lo tanto, el «arte» de la construcción de modelos implica simplificar la realidad para ayudarnos a comprender el problema que queremos resolver.
Pero encontrar el punto medio donde la simplicidad es útil no siempre es una tarea sencilla.
Aquí te mostramos qué debes tener en cuenta a la hora de construir tu modelo para no sub-estimar ni sobre-estimar.
Tabla de contenidos
Resumiendo el dilema
Podemos decir que existen 3 casos:
Modelo sub-especificado
Si eliges muy pocas variables puedes obtener un modelo mal detallado y producir estimaciones sesgadas.
Cuando falta una o más variables predictoras importantes, los coeficientes de regresión serán sesgados y las predicciones de la respuesta también serán sesgadas.
Modelo correcto
Si eliges el número de variables justas tendrás un modelo sin problemas y con estimaciones precisas.
Si tu modelo contiene todos los predictores relevantes, incluyendo cualquier transformación necesaria y los términos de interacción, los coeficientes de regresión serán insesgados y las predicciones de la respuesta también serán insesgadas.
Modelo sobre-especificado
Si eliges un modelo con demasiadas variables tendrás un modelo excesivamente especificado y las estimaciones serán poco precisas.
Cuando la regresión contiene una o más variables predictoras redundantes se producen coeficientes de regresión sin sesgo y predicciones no sesgadas de la respuesta. Los predictores redundantes conducen a problemas como los errores estándar inflados para los coeficientes de regresión y están asociados con la multicolinearidad. Este modelo de regresión puede usarse con precaución para la predicción de la respuesta, pero no debe utilizarse para atribuir el efecto de un predictor en la respuesta. Recuerda además que el modelo se vuelve más complicado y difícil de entender de lo necesario.
¿A qué me refiero con estimaciones precisas o insesgadas?
Imagina que todos los días te pesas en una balanza. La balanza puede tener errores en su estimación del peso cada día pero lo que necesitamos es que nos de valores correctos en promedio – en ese caso, la balanza sería insesgada-.
La mejor estrategia
-
Ten claro tu objetivo y pregunta de investigación. Saber cómo vas a utilizar su modelo de regresión puede ayudarte mucho en la fase de construcción del modelo. ¿Qué modelo necesitas para alcanzar los objetivos de tu estudio?
-
¿Tienes algunos predictores particulares de interés? Si es así, debes asegurarte de que su modelo final los incluya.
-
¿Estás interesado en predecir la respuesta? Si es así, entonces no te preocupes demasiado por la multicolinealidad.
-
¿Estás interesado en los efectos que predictores específicos tienen sobre la respuesta? Si es así, debes tener cuidado con la multicolinealidad.
-
¿Estás interesado en una descripción resumida?
-
Identifica todos los posibles predictores candidatos. Asegúrate de identificar todos los posibles predictores importantes, si no los consideras, no hay posibilidad de que aparezcan en tu modelo final.
-
Explora tus datos (resúmenes y gráficos). Sí, es un paso obvio pero muchos investigadores lo subestiman y puede hacerte tirar por la borda horas de arduo trabajo. Comprueba si hay valores atípicos (outliers) y/o valores faltantes, o errores en la base de datos, de manera uni- y bivariada. Te permitirá tener una idea previa del tipo de relación que existe entre las variables (lineales o no lineales, multicolinealidad, etc.).
Artículos que te pueden interesar:
Errores Comunes que Puedes Evitar con un Simple Gráfico
Cómo calcular resúmenes por grupo rápidamente
¿Cómo Lidiar Con Los Datos Atípicos (Outliers)?
- Reflexiona sobre cómo es tu variable respuesta y qué tipo modelo debes utilizar. Para elegir el modelo de regresión que debes aplicar a tus datos debes primero tener en cuenta el modelo más sencillo, el modelo de regresión lineal (LM) y evalúar los supuestos clásicos de la estadística.
Artículos que te pueden interesar:
¿Qué modelo de regresión debería elegir?
-
Evaluación del modelo basado en las predicciones. Utiliza validación cruzada (crossvalidation); lo que haces es dividir tu conjunto de datos en trozos, construyes el modelo con uno de ellos, luego predices los resultados con el resto del conjunto de datos y calculas la diferencia entre lo observado y lo predicho por el modelo. Puedes repetir este proceso varias veces y calcular una métrica de «performance». El modelo con una mayor bondad de ajuste ajustada (R2 adj) o menor error cuadrático medio de predicción (RMSE) será considerado como un mejor modelo predictivo. Finalmente podrías comparar dos modelos en base a su precisión en las predicciones.
-
Evaluación del modelo basado en la bondad de ajuste. Puedes comparar modelos mediante alguna métrica de «performance» (e.g. AIC, BIC, Cp), y si los modelos están anidados puedes utilizar una comparación formal con LRT, Chi-squared o F-test. Lo que realizas básicamente es controlar si al agregar nuevas variables explicativas o interacciones el modelo mejora.
¿Qué es el criterio de información de Akaike (AIC)?
El AIC (“Akaike’s Information Criterion”) sirve para comparar modelos.
Este criterio tiene en cuenta tanto el ajuste del modelo como su complejidad de acuerdo a la fórmula: -2*log-likelihood + k*npar donde el primer término mide el ajuste (es la devianza) y el segundo la complejidad (npar es el número de parámetros y k = 2). Es decir, el segundo término es de penalización y evita el sobreajuste (aumentando el número de parámetros del modelo suele mejorar la bondad del ajuste sin impli).
Dado un conjunto de modelos candidatos para los datos, el modelo preferido es el que tiene elvalor mínimo en el AIC. De los AICs de un conjunto de modelos se puede derivar un índice de ‘peso’ relativo de los modelos (a través de las diferencias con el AIC más bajo, al que se le da el valor 0) y de las variables (como suma de los pesos de los modelos donde aparece una variable dada).
Existe también el AIC corregido (AICc) que es una variante del AIC para tamaños muestrales bajos (pocos datos).
AIC no equivale a significación (p-valor), se plantea dentro de una concepción de la estadística distinta y alternativa. El AIC no proporciona una prueba de un modelo en el sentido de probar una hipótesis nula , es decir AIC puede decir nada acerca de la calidad del modelo en un sentido absoluto. Si todos los modelos candidatos encajan mal, el AIC no dará ningún aviso de ello.
- Utiliza procedimientos de selección de variables para encontrar el término medio entre un modelo no especificado y un modelo con variables redundantes. Dos posibles procedimientos de selección de variables son la regresión por etapas y la regresión de los mejores subconjuntos. Puedes utilizar criterios como el criterio de información de Akaike (AIC) para ello.
¿Qué son los modelos de selección automática?
Hay amigos y enemigos de estos métodos. Principalmente los detractores critican problemas cuando nuestro objetivo es crear modelos descriptivos:
- los usuarios se olvidan de revisar las variables incluidas, se debe controlar el efecto de posibles variables de confusión, variables correlacionadas y variables que no tiene sentido considerar de manera conjunta. Los métodos automáticos no producirán necesariamente el mejor modelo si hay predictores redundantes. según el punto de partida el método puede proporcionar un modelo distinto, no son estables.
- la elección del punto de corte para seleccionar el mejor modelo es arbitraria. rara vez se prueban con nuevos datos y muchas veces fallan cuando se realiza esta comprobación.
- como los coeficientes del modelo dependen de los demás términos incluidos la selección de variables explicativas debería estar guiado por el conocimiento previo que se tenga del tema.
Si aún así optas por la selección automática es preferible utilizar backward o stepwise en lugar de forward debido a que ésta última tiene el inconveniente de que al añadir una nueva variable pude e hacer que una o más variables ya incluidas se vuelvan no significativas.
NOTA: hay métodos más actuales como LASSO o LAR.
- Comprueba el comportamiento de los residuos. Si los residuos sugieren problemas con el modelo, pruebe con una forma funcional diferente de los predictores o elimine algunos de los términos de interacción. Si ninguno de los modelos proporciona un ajuste satisfactorio deberá tomar más datos, o identificar diferentes predictores o otro tipo diferente de modelo.
Artículos que te pueden interesar:
¿Cómo Validar Tu Modelo De Regresión?
Ejemplo de comparación y selección de modelos con R
Imaginemos un estudio donde se desea evaluar el efecto tóxico de un pesticida en una determinada especie de insecto. Los datos consisten en: tasa de dosis del pesticida (dose x1, desconocida), peso corporal del insecto (weight x2, en gramos) y tasa de acción tóxica (effect y, medida como tiempo de muerte en minutos).
Los datos del ejemplo son del Dr. Bret Larget, profesor de estadística y botánica de la University of Wisconsin (puedes descargarlos desde su web https://www.stat.wisc.edu/~larget/ o aquí https://www.stat.wisc.edu/~ane/st572/data/toxic.txt ).
> toxic = read.table ("toxic.txt", header = T) #adjunto los datos
> toxic
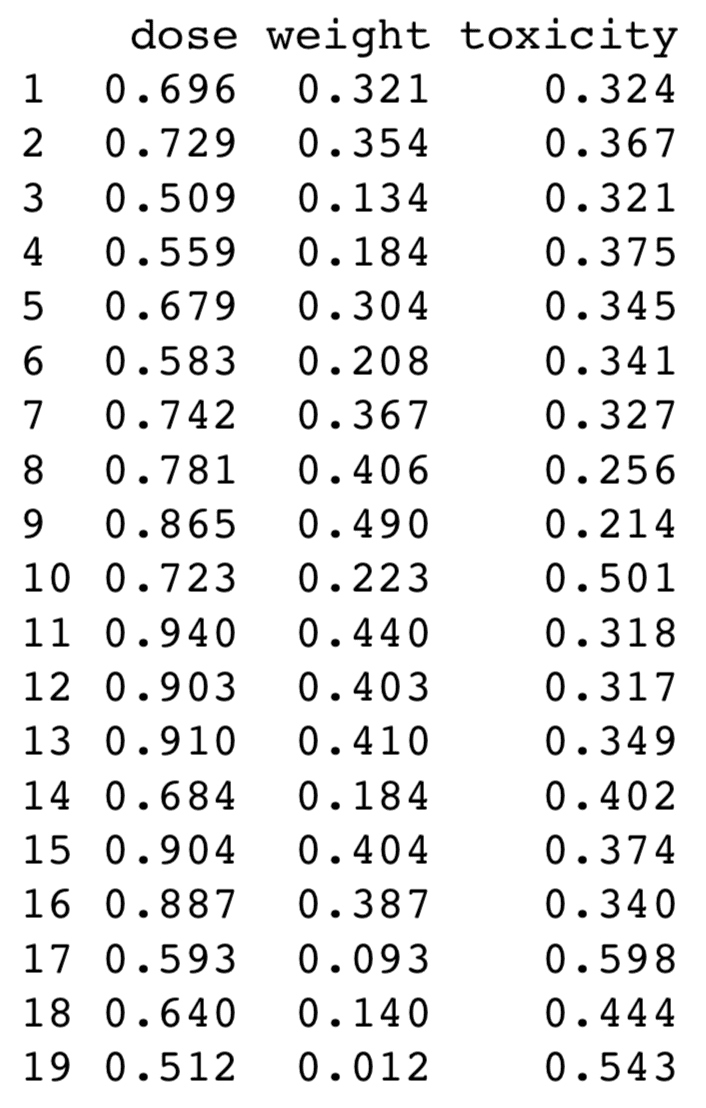
> str (toxic)
> attach(toxic)Posibles modelos que podemos ajustar:
yi~β0+ei
yi~β0+β2*xi2+ei
yi~β0+β1*xi1+ei
yi~β0+β1*xi1+β2*xi2+ei
donde ei corresponden a los errores, β0 al intercepto, β1 y β2 son los coeficientes de las dos variables explicativas consideradas, x1 y x2, respectivamente.
Construimos en R todos los modelos:
> toxic0.lm = lm(effect ~ 1)
> toxic1.lm = lm(effect ~ dose)
> toxic2.lm = lm(effect ~ weight)
> toxic12.lm = lm(effect ~ dose + weight)
> toxic21.lm = lm(effect ~ weight + dose)Tabla de resumen y tabla ANOVALa tabla de resumen y la tabla ANOVA del modelo lineal indican pruebas de hipótesis distintas.
La función summary indica las pruebas t que contrastan si un parámetro es cero en el modelo que incluye todos los demás coeficientes.
La función anova indica los resultados de la prueba F que contrasta si un parámetro es cero en el modelo incluyendo solo los parámetros indicados anteriormente en la tabla.
> summary(toxic12.lm)
Call:
lm(formula = effect ~ dose + weight)
Residuals:
Min 1Q Median 3Q Max
-0.081512 -0.023945 -0.003421 0.022278 0.094310
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.22281 0.08364 2.664 0.01698 *
dose 0.65139 0.17305 3.764 0.00170 **
weight -1.13321 0.18044 -6.280 1.10e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.0466 on 16 degrees of freedom
Multiple R-Squared: 0.7796, Adjusted R-squared: 0.752
F-statistic: 28.3 on 2 and 16 DF, p-value: 5.57e-06
> anova(toxic12.lm)
Analysis of Variance Table
Response: effect
Df Sum Sq Mean Sq F value Pr(>F)
dose 1 0.037239 0.037239 17.152 0.0007669 ***
weight 1 0.085629 0.085629 39.440 1.097e-05 ***
Residuals 16 0.034738 0.002171
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Lo que estamos evaluando son las siguientes hipótesis nulas:
H0:[β0 =0|β1,β2] p=0.01698
H0:[β1 =0|β0,β2] p=0.001697
H0:[β2 =0|β0,β1] p=1.097e-05
H0:[β1 =β2=0|β0] p=5.57e-06
H0:[β1 =0|β0] p=0.0007669
H0:[β2 =0|β0,β1] p=1.097e-05
NOTA: El contraste β1=0 (efecto dose) da diferente si weight está incluido en el modelo o no, luego explicaré el por qué.
Para contrastar la misma hipótesis la prueba F y la prueba t coinciden: (-2.293)^2=5.26**:**
> summary(toxic1.lm)
...
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.6049 0.1036 5.836 1.98e-05 ***
dose -0.3206 0.1398 -2.293 0.0348 *
Residual standard error: 0.08415 on 17 degrees of freedom
Multiple R-squared: 0.2363, Adjusted R-squared: 0.1914
F-statistic: 5.259 on 1 and 17 DF, p-value: 0.03485
> anova(toxic0.lm, toxic1.lm)
Analysis of Variance Table
Model 1: toxicity ̃ 1
Model 2: toxicity ̃ dose
Res.Df RSS Df Sum of Sq F Pr(>F)
1 18 0.1576
2 17 0.1204 1 0.0372 5.26 0.035 *Comparación de modelos con la función anova y drop1.Debes ser cuidadoso al utilizar la función anova con un único modelo: ¡el orden importa!
cada variable predictora se agrega de una en una (con suma de cuadrados SS de tipo I) por lo cual el orden en el que se ingresan dichas variables importa y produce resultados distintos.
> anova(toxic12.lm)
Response: toxicity
Df Sum Sq Mean Sq F value Pr(>F)
dose 1 0.037239 0.037239 17.152 0.0007669 ***
weight 1 0.085629 0.085629 39.440 1.097e-05 ***
Residuals 16 0.034738 0.002171
> anova(toxic21.lm)
Response: toxicity
Df Sum Sq Mean Sq F value Pr(>F)
weight 1 0.092107 0.092107 42.424 7.147e-06 ***
dose 1 0.030761 0.030761 14.168 0.001697 **
Residuals 16 0.034738 0.002171EJERCICIO: ¿Cuál sería la forma apropiada de contrastar el efecto del peso weight? ¿y para contrastar el efecto dosis dose?
¿A qué me refiero con el orden?
Las siguientes comparaciones producen el mismo resultado porque en ambas estamos evaluando el efecto de dose:
> anova(toxic2.lm, toxic12.lm) #lm(effect ~ weight) vs lm(effect ~ dose + weight)
> anova(toxic2.lm, toxic21.lm) # lm(effect ~ weight) vs lm(effect ~ weight + dose)Sin embargo, las siguientes hipótesis son distintas y por ende los resultados también lo son:
> anova( toxic0.lm , toxic1.lm ) # H0:[β1 =0|β0]
> anova( toxic2.lm , toxic21.lm ) # H0:[β1 =0|β0,β2]EJERCICIO: Prueba ahora realizar los siguientes contrastes
- H0: β2=0| β0
- H0: β2=0| β0, β1
- H0: β1=β2=0| β0
Si utilizas la función drop1 ¡el orden no importa!
Aquí se utiliza la prueba F para contrastar cada predictor luego de dar cuenta de los demás (con SS tipo III) por lo cual el orden de los predictores no importa.
> drop1(toxic12.lm, test="F")
Single term deletions
Model: toxicity ̃ dose + weight
DfSumofSq RSS AIC F value Pr(F) <none> 0.034738 -113.783
dose 1 0.030761 0.065499 -103.733 14.168 0.001697 ** weight 1 0.085629 0.120367 -92.171 39.440 1.097e-05 ***
> drop1(toxic21.lm, test="F")
Single term deletions
Model: toxicity ̃ weight + dose
DfSumofSq RSS AIC F value Pr(F) 0.034738 -113.783
<none>
weight 1 0.085629 0.120367 -92.171 39.440 1.097e-05 ***
dose 1 0.030761 0.065499 -103.733 14.168 0.001697 **Los coeficientes de regresión deben interpretarse en el contexto de las demás variables incluidas en el modelo.
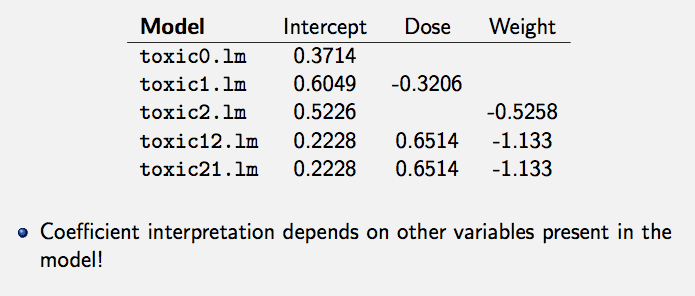
Los resultados son diferentes cuando las variables están correlacionadas (i.e. multicolinealidad)
1) Encontramos poca evidencia del efecto dose cuando ignoramos el efecto de weight.
Encontramos gran evidencia del efecto dose luego de ajustar el efecto de weight.
Aquí vemos que dose y weight están correlacionadas, por eso los resultados difieren.
- El efecto dose es negativo si está solo en el modelo. Esto significaría que al aumentar la dosis la tasa de acción tóxica disminuye, lo cual es contraintuitivo… ¡debería llamarnos la atención!
> summary(toxic1.lm)
…
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.6049 0.1036 5.836 1.98e-05 ***
dose -0.3206 0.1398 -2.293 0.0348 *
Residual standard error: 0.08415 on 17 degrees of freedom
Multiple R-squared: 0.2363, Adjusted R-squared: 0.1914
F-statistic: 5.259 on 1 and 17 DF, p-value: 0.03485
> summary(toxic12.lm)
…
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.22281 0.08364 2.664 0.01698 *
dose 0.65139 0.17305 3.764 0.00170 **
weight -1.13321 0.18044 -6.280 1.10e-05 ***
EJERCICIO: ahora analiza tú la correlación entre dose y weight, y cuéntanos qué ocurre.
Como última reflexión, no hay que olvidar que no hay necesariamente un único buen modelo para un conjunto dado de datos, sino que pueden existir varios modelos igualmente satisfactorios.
Antes de irte, ¡Déjanos tu comentario! Saludos ?
Algunas referencias que les pueden interesar
- Burnham, K. P., Anderson, D. R., & Huyvaert, K. P. (2011). AIC model selection and multimodel inference in behavioral ecology: some background, observations, and comparisons. Behavioral Ecology and Sociobiology, 65(1), 23-35.
- Akaike, Hirotugu (1974), «A new look at the statistical model identification», IEEE Transactions on Automatic Control 19 (6): 716-723, doi:10.1109/TAC.1974.1100705, MR 0423716.
- Anderson, D. R. (2008), Model Based Inference in the Life Sciences, Springer.
- Burnham, K. P.; Anderson, D. R. (2002), Model Selection and Multimodel Inference: A Practical Information-Theoretic Approach (2nd edición), Springer-Verlag, ISBN 0-387-95364-7.
- Burnham, K. P.; Anderson, D. R. (2004), «Multimodel inference: understanding AIC and BIC in Model Selection», Sociological Methods and Research 33: 261-304.
- Cavanaugh, J. E. (1997), «Unifying the derivations of the Akaike and corrected Akaike information criteria», Statistics and Probability Letters 31: 201-208.


