
Se llama «el cuarteto de Anscombe» en honor al estadístico Anscombe que creó 4 conjuntos de datos en los años 70 para convencer a sus colegas de la…
Recuerda lo siguiente:
¡Realizar gráficos apropiados es parte esencial del análisis de datos!
Hace tiempo que quería enseñarte un ejemplo muy bonito que retrata esta cuestión.
Se llama «el cuarteto de Anscombe» en honor al estadístico Anscombe que creó 4 conjuntos de datos en los años 70 para convencer a sus colegas de la importancia del análisis gráfico de los datos.
Puedes ver el artículo original aquí.
Contenidos
EL CUARTETO DE ANSCOMBE
Los 4 conjuntos de datos x-y tienen las mismas propiedades estadísticas tradicionales (media, varianza, correlación, línea de regresión, etc.), pero son bastante diferentes:
- Número de observaciones (n): 11
- Media de la variable x: 9.0
- Desviación típica de la variable x: 3.32
- Media de la variable y: 7.5
- Desviación típica de la variable y: 2.03
- Coeficiente de correlación lineal: 0.816
- Ecuación de regresión lineal: y = 3 + 0,5 · x
- Suma de cuadrados de los residuos: 13,75 (con 9 grados de libertad)
- Error estándar del parámetro b1: 0,118
- R-cuadrado, R2: 0,667
Puedes acceder a los datos desde el software R de la siguiente manera:
> require(stats); require(graphics)
> anscombe
x1 x2 x3 x4 y1 y2 y3 y4
1 10 10 10 8 8.04 9.14 7.46 6.58
2 8 8 8 8 6.95 8.14 6.77 5.76
3 13 13 13 8 7.58 8.74 12.74 7.71
4 9 9 9 8 8.81 8.77 7.11 8.84
5 11 11 11 8 8.33 9.26 7.81 8.47
6 14 14 14 8 9.96 8.10 8.84 7.04
7 6 6 6 8 7.24 6.13 6.08 5.25
8 4 4 4 19 4.26 3.10 5.39 12.50
9 12 12 12 8 10.84 9.13 8.15 5.56
10 7 7 7 8 4.82 7.26 6.42 7.91
11 5 5 5 8 5.68 4.74 5.73 6.89MODELAR A CIEGAS
Si ajustas los 4 modelos posibles puedes comprobar que se obtiene la misma recta de regresión y el mismo valor de bondad de ajuste (R2) para los 4 conjuntos de datos.
> ff <- y ~ x
> mods <- setNames(as.list(1:4), paste0("lm", 1:4))
> for(i in 1:4) {
+ ff[2:3] <- lapply(paste0(c("y","x"), i), as.name)
+ ## or ff[[2]] <- as.name(paste0("y", i))
+ ## ff[[3]] <- as.name(paste0("x", i))
+ mods[[i]] <- lmi <- lm(ff, data = anscombe)
+ print(anova(lmi))
+ }
Analysis of Variance Table
Response: y1
Df Sum Sq Mean Sq F valuePr(>F)
x11 27.510 27.510017.99 0.00217 **
Residuals9 13.7631.5292
---
Signif. codes:0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Analysis of Variance Table
Response: y2
Df Sum Sq Mean Sq F valuePr(>F)
x21 27.500 27.500017.966 0.002179 **
Residuals9 13.7761.5307
---
Signif. codes:0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Analysis of Variance Table
Response: y3
Df Sum Sq Mean Sq F valuePr(>F)
x31 27.470 27.470017.972 0.002176 **
Residuals9 13.7561.5285
---
Signif. codes:0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Analysis of Variance Table
Response: y4
Df Sum Sq Mean Sq F valuePr(>F)
x41 27.490 27.490018.003 0.002165 **
Residuals9 13.7421.5269
---
Signif. codes:0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1¡Como puedes ver los modelos ajustados son muy similares!
REALIZAR UN GRÁFICO A TIEMPO
Sin embargo, si graficas los 4 conjuntos de datos puedes ver que solo uno de ellos debería ser representado mediante un modelo de regresión lineal simple.
> op <- par(mfrow = c(2, 2), mar = 0.1+c(4,4,1,1), oma = c(0, 0, 2, 0))
> for(i in 1:4) {
+ ff[2:3] <- lapply(paste0(c("y","x"), i), as.name)
+ plot(ff, data = anscombe, col = "red", pch = 21, bg = "orange", cex = 1.2,
+ xlim = c(3, 19), ylim = c(3, 13))
+ abline(mods[[i]], col = "blue")
+ }
> mtext("Anscombe's 4 Regression data sets", outer = TRUE, cex = 1.5)
> par(op)
> par(mfrow=c(2,2))
> plot(mods[[1]], col = "red", pch = 21, bg = "orange", cex = 1.2)
> plot(mods[[2]], col = "red", pch = 21, bg = "orange", cex = 1.2)
> plot(mods[[3]], col = "red", pch = 21, bg = "orange", cex = 1.2)
> plot(mods[[4]], col = "red", pch = 21, bg = "orange", cex = 1.2)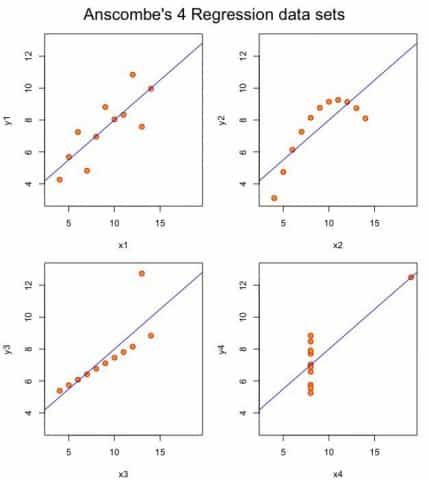
¿Cómo se interpretan estos datos?
- En el primer caso (arriba a la izquierda) obtienes una relación lineal bastante adecuada,
- en el segundo (arriba derecha) probablemente deberías utilizar una relación no lineal para su modelado y por tanto el R2 obtenido no es relevante,
- mientras que en el tercero y cuarto gráfico (debajo) deberías investigar la presencia de outliers.
- Además, el cuarto caso (debajo a la derecha) indica un diseño experimental inadecuado ya que la variable x4 toma prácticamente siempre los mismos valores.
CONOCER LA HISTORIA COMPLETA
Este ejemplo deja una clara moraleja: la importancia de explorar gráficamente los datos antes de analizarlos.
Veamos su consecuencia en 3 tipos de análisis distintos:
1. Los estadísticos descriptivos
- Los estadísticos descriptivos no te dan una información completa sobre cómo son nuestros datos. Por ejemplo, son sensibles a los outliers, como se puede ver en el tercer y cuarto ejemplo. Es decir, ¡Recuerda siempre primero graficar tus datos y evaluar la presencia de outliers!
2. El coeficiente de correlación lineal
-
Has visto que puedes obtener valores altos de correlación lineal cuando en realidad la relación de las variables es no lineal, esto ocurre cuando las variables no tienen distribución normal o también debido a la presencia de outliers. Por ello, _¡comprueba siempre los supuestos del análisis que uses!_3. La regresión lineal
-
La regresión lineal también es sensible al incumplimiento de sus supuestos y a la presencia de outliers, Debes evaluar los supuestos del modelo, y su ajuste, mediante gráficos. Cuando estas trabajando con un modelo de regresión lineal simple (i.e. una variable explicativa o predictor) basta con utilizar modelos de dispersión. Sin embargo, cuando te encuentras con múltiples variables explicativas y quieres ajustar un modelo de regresión múltiple será más sencillo que evalúes el ajuste del modelo mediante los gráficos de residuos.
-
Además, al igual que ocurre con el coeficiente de correlación, debes tener cuidado en la interpretación que le demos al coeficiente de determinación (o R2), ya que:
-
resumen en un único valor toda una nube de puntos. Ambos son solo estadísticos de descripción, no una validación del modelo, y por tanto no se pueden utilizar para comparar modelos. Los 4 conjuntos de datos obtienen los mismos valores de R2 y sin embargo el modelo de regresión solo puede ser aplicado en el primer caso (arriba a la izquierda).
-
hay que tener cuidado a la hora de interpretar un valor alto de R2 como indicador de un buen ajuste de los datos al modelo, porque otra función puede describir mejor la tendencia de los datos, como en el segundo ejemplo (arriba a la derecha).
-
pueden ser afectados fuertemente por tan solo uno o pocos datos (outliers), como en el tercer y cuarto ejemplo (gráficos inferiores).
-
En conclusión, ¡Realiza el diagnóstico gráfico de tu modelo para validarlo y ten cuidado con la interpretación del R2!
¡Si te ha parecido un buen ejemplo deja tus comentarios debajo!


