

Elegir el modelo estadístico correcto es clave para obtener resultados válidos y útiles. En esta guía aprenderás a distinguir entre los distintos modelos de regresión, sus supuestos, limitaciones y cuándo conviene usar cada uno.
Al final, te llevarás un esquema visual que resume todo de forma práctica.
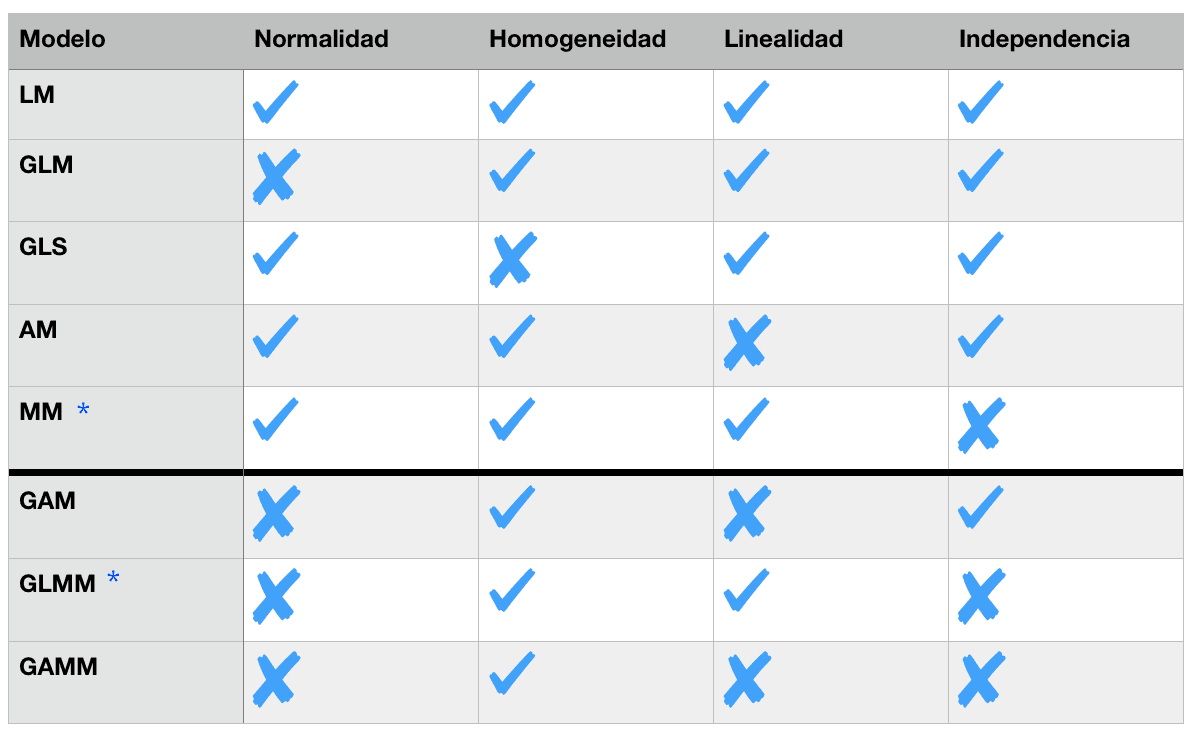
MODELO LINEAL (LM): Comienza por lo básico
Para elegir el modelo de regresión que debes aplicar a tus datos debes primero tener en cuenta el modelo más sencillo, el modelo de regresión lineal (LM).
¿Qué es un Modelo lineal, LM (Linear Models)?
Es un modelo que relaciona de manera lineal (siguiendo una recta) una variable respuesta con una o más variables predictoras o explicativas. Requiere de que se cumplan una serie de supuestos sobre los datos que detallo a continuación.
4 supuestos (limitaciones) del modelo lineal:
1. Normalidad
Los residuos (o errores=la diferencia entre las observaciones y las predicciones del modelo) del modelo siguen una distribución normal (forma de campana de Gauss). Generalmente si la respuesta no se distancia mucho de la normalidad no tendremos problemas. Para saber si la respuesta sigue o no una distribución normal primero debemos pensar en el tipo de variable respuesta que tenemos, lo más sencillo. Por ejemplo, si estamos ante una respuesta binaria los datos no serán normales ni existirá ninguna transformación útil para que lo sea. En el caso de que esto no sea tan obvio, se puede chequear realizando un histograma o gráfico QQ con los residuos del modelo. En el histograma deberíamos encontrar un patrón de campana y en el gráfico QQ unos puntos que se localizan sobre la diagonal.
2. Homogeneidad
Cuando la dispersión de los datos no es la misma para cada valor del predictor o variable explicativa. Si el incumplimiento no es demasiado serio no tendremos problema. La manera de chequearlo es traficar los residuos en función de los valores ajustados por el modelo. La dispersión debería ser la misma para todo el rango de valores ajustados.
3. Linealidad
La relación entre la respuesta y la variable predictora es de tipo lineal o monotónica.
4. Independencia
Si la respuesta para un determinado valor del predictor está influenciado por otro valor del predictor. Por ejemplo, piensen en el caso de datos temporales, si medimos la temperatura media del día es más probable que se parezca a la temperatura media del día anterior. Es el supuesto más delicado porque invalida las pruebas estadísticas F y t. Generalmente incumplimos este supuesto por la naturaleza de nuestros datos, datos temporales o espaciales (los sitios más cercanos serán más parecidos entre sí respecto al resto).
Muchos estudiantes discuten el uso de técnicas gráficas, en lugar de pruebas estadísticas, para evaluar los supuestos debido a que requiere cierto grado de subjetividad. El problema de utilizar pruebas estadísticas para ello es que la mayoría asumen normalidad y muchas veces no nos permiten detectar problemas de outliers o no-linealidad. Pueden ver el ejemplo Anscome sobre la importancia de los gráficos.
NOTA: Recuerden pensar si vuestro datos cumplen con los supuestos, dada su naturaleza (e.g. binaria), antes de ajustar el modelo y/o ayudarse de gráficos exploratorios para evaluarlos. Aún así, tendrán una segunda instancia de evaluación del modelo en la validación con los residuos.
¿Qué pasa si tus datos no cumplen los supuestos?
Ahora veremos las extensiones del LM para casos donde no se cumple uno o más de estos supuestos.NOTA: He señalado con un signo de menos («-«) aquella condición que no es limitante para el modelo en consideración, por ejemplo, «-Normalidad» significa que no asume la normalidad de los datos.
GLM: Modelos Lineales Generalizados (-Normalidad)
Los GLM (Generalised Linear Models) nos sirven para datos que no cumplen con el supuesto de normalidad, permiten modelar datos de conteo, datos binarios, datos de proporciones y datos inflados por ceros.
GLS: Mínimos Cuadrados Generalizados (-Homogeneidad)
Los GLS (Generalised Least Squares models) nos sirven para para datos que no cumplen con el supuesto de homogeneidad o varianza constante, porque permite modelar la heterogeneidad mediante covariables.
AM: Modelos Aditivos (-Linealidad)
Los AM (Additive Models) nos sirven para datos que no cumplen con el supuesto de linealidad, permiten modelar la función no-lineal que relaciona las variables de estudio mediante funciones de suavizado.
MM: Modelos Mixtos (-Independencia)
Los MM (Mixed Models) son útiles para datos donde no se cumple el supuesto de independencia de las observaciones, permite modelar datos anidados (o de panel o jerárquicos o multinivel), medidas repetidas y datos con correlación temporal o espacial.
MODELOS COMBINADOS: cuando se rompen múltiples supuestos
GAM: Modelos Aditivos Generalizados
Los GAM (Generalised Additive Models) se utilizan cuando nuestros datos que no cumplen con el supuesto de normalidad ni el de linealidad.
GLMM: Modelos Lineales Mixtos Generalizados
Los GLMM (Generalised Linear Mixed Models) se utilizan para datos que no cumplen con el supuesto de normalidad ni el de independencia. Por ejemplo, permiten modelar datos anidados o estructuras de correlación temporal o espacial, para datos de conteo o binomiales. Son la combinación de GLM+MM
GAMM: Modelos Aditivos Mixtos Generalizados
Los GAMM (Generalised Additive Mixed Models) los utilizaremos cuando los datos no cumplen con el supuesto de normalidad, ni el de linealidad ni el de independencia. Por ejemplo para modelar datos anidados con comportamiento oscilatorio y una respuesta de conteo. Son la combinación de GAM+MM
Esquema final
(*) Luego de una interesante discusión en Linkedin con Adrián Olszewski, sobre el supuesto de homogeneidad de varianza en modelos mixtos MM y modelos mixtos generalizados GLMM, he decidido agregar el siguiente comentario. Los modelos mixtos permiten modelar casos simples de heterocedasticidad; los componentes de efecto aleatorio de los modelos de efectos mixtos infieren la varianza asociada con la pertenencia al grupo (Gelman & Hill, 2006; Schielzeth & Nakagawa, 2013), pero asumen errores intragrupo homocedásticos. Por lo tanto, dependiendo de la formulación, los GLMM pueden tener en cuenta la heteroscedasticidad de los datos. No obstante, los escenarios más avanzados requieren un enfoque diferente, como la estimación GLS/GEE o, herramientas flexibles con una especificación cuidadosa de los componentes de covarianza.


